並列コードのプロファイル
この例では、並列プール内のワーカーで並列プロファイラーを使用して並列コードをプロファイルする方法を説明します。
並列プールを作成します。
numberOfWorkers = 3; pool = parpool(numberOfWorkers);
Starting parallel pool (parpool) using the 'Processes' profile ... Connected to parallel pool with 3 workers.
mpiprofile を有効にして、並列プロファイル データを収集します。
mpiprofile on並列コードを実行します。この例の目的上、一連の値に対して反復するシンプルな parfor ループを使用します。
values = [5 12 13 1 12 5]; tic; parfor idx = 1:numel(values) u = rand(values(idx)*3e4,1); out(idx) = max(conv(u,u)); end toc
Elapsed time is 51.886814 seconds.
コードの終了後、mpiprofile viewer を呼び出して並列プロファイラーから結果を表示します。このアクションは、プロファイル データの収集停止も行います。
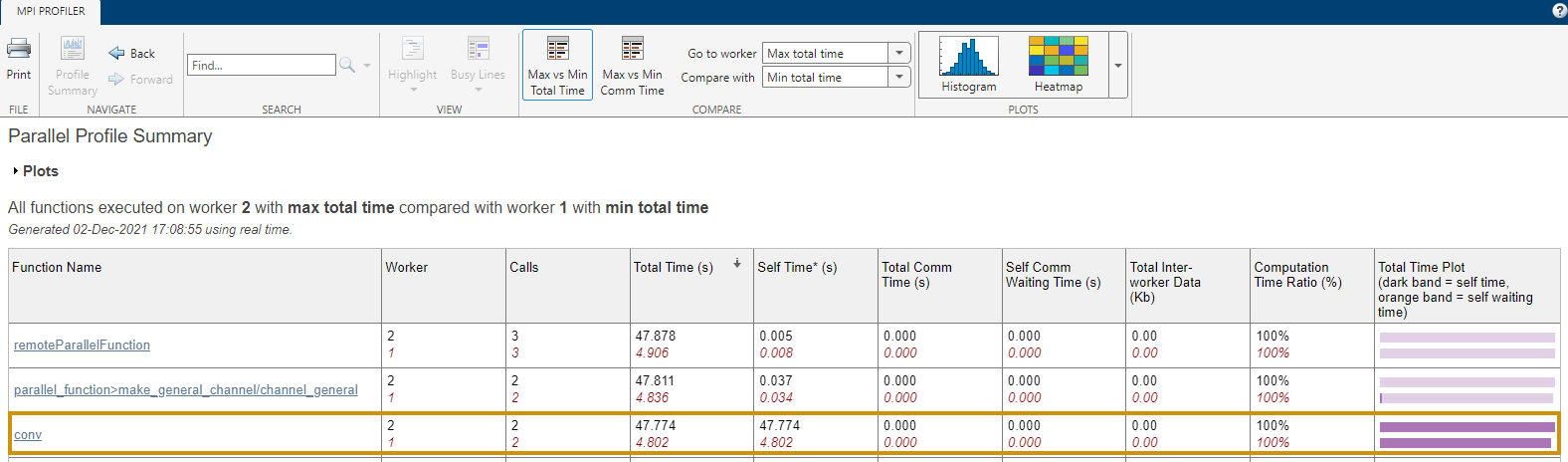
mpiprofile viewerレポートには、ワーカーで実行される各関数の実行時間に関する情報が表示されます。各ワーカーで最も長い時間を要する関数を調べることができます。
通常、合計実行時間が最長と最短のワーカーを比較すると便利です。これを行うには、レポートの [最長と最短合計時間] をクリックします。この例では、あるワーカーで conv が複数回実行され、他のワーカーより大幅に長い時間を要したことが観察されます。この観察は、作業負荷がワーカー間に均等に分散されていなかった可能性を示唆しています。
各反復の作業負荷が不明の場合は、次のサンプル コードのように反復をランダム化することを推奨します。
values = values(randperm(numel(values)));
parforループ内の各反復の作業負荷が既知の場合は、parforOptionsを使用して、ワーカーのサブレンジへの反復の分割を制御します。詳細については、parforOptionsを参照してください。
この例では、values(idx) が大きくなるほど、反復の計算量が多くなります。values 内の値の連続するペアにはそれぞれ、最大および最小の計算量が表示されています。作業負荷がより良く分散されるように、parfor の反復をサイズ 2 のサブレンジに分割する parfor のオプション セットを作成します。
opts = parforOptions(pool,"RangePartitionMethod","fixed","SubrangeSize",2);
並列プロファイラーを有効にします。
mpiprofile on前と同じコードを実行します。parfor のオプションを使用するには、parfor の 2 番目の入力引数に渡します。
values = [5 12 13 1 12 5]; tic; parfor (idx = 1:numel(values),opts) u = rand(values(idx)*3e4,1); out(idx) = max(conv(u,u)); end toc
Elapsed time is 33.813523 seconds.
並列プロファイラーの結果を可視化します。
mpiprofile viewerこのレポートの [最長と最短合計時間] を選択して、合計実行時間が最短と最長のワーカーを比較します。今回はすべてのワーカーで、conv の複数回の実行に同様な時間がかかっています。今回の作業負荷はより良く分散されています。
