ループ ローリング
Target Language Compiler の最適化機能の 1 つに、ループ ローリングの内部的なサポートがあります。ループ動作のコード生成について、指定したしきい値に基づいて、ループを展開するかループのまま残す (ロールする) ことができます。
ループ ローリングは、不連続的な信号の概念と関連しています。次のモデルについて考えます。
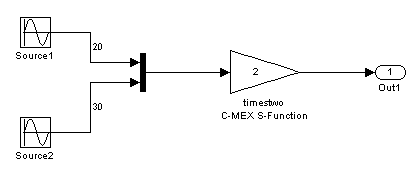
timestwo S-Function への入力が 2 つの異なるメモリ位置にある 2 つの配列から取得されています。一方は source1 の出力で、もう一方はブロック source2 の出力です。これは、Mux ブロックを "バーチャル" にし、Mux ブロックのコードを明示的に生成しないことで、その評価にプロセッサのサイクルが使用されないようにする最適化によるものです (つまり、このブロックは、ブロック線図で便宜的に使用される純粋なグラフィックス表記になります)。そのため、この場合の model.rtw
Block {
Type "S-Function"
MaskType "S-function: timestwo"
BlockIdx [0, 0, 2]
SL_BlockIdx 2
GrSrc [0, 1]
ExprCommentInfo {
SysIdxList []
BlkIdxList []
PortIdxList []
}
ExprCommentSrcIdx {
SysIdx -1
BlkIdx -1
PortIdx -1
}
Name "<Root>/timestwo C-MEX S-Function"
SLName "<Root>/timestwo \nC-MEX S-Function"
Identifier timestwoCMEXSFunction
TID 0
RollRegions [0:19, 20:49]
NumDataInputPorts 1
DataInputPort {
SignalSrc [b0@20, b1@30]
SignalOffset [0:19, 0:29]
Width 50
RollRegions [0:19, 20:49]
}
NumDataOutputPorts 1
DataOutputPort {
SignalSrc [b2@50]
SignalOffset [0:49]
Width 50
}
Connections {
InputPortContiguous [no]
InputPortConnected [yes]
OutputPortConnected [yes]
OutputPortBeingMerged [no]
DirectSrcConn [no]
DirectDstConn [yes]
DataOutputPort {
NumConnPoints 1
ConnPoint {
SrcSignal [0, 50]
DstBlockAndPortEl [0, 4, 0, 0]
}
}
}
.
.
.この model.rtwRollRegion のエントリが、数値 1 つではなく、2 つの数値のグループになっていることがわかります。これは、メモリに入力信号のグループが 2 つあることを示しています。生成コードは次のようになります。
/* S-Function Block: <Root>/timestwo C-MEX S-Function */
/* Multiply input by two */
{
int_T i1;
const real_T *u0 = &contig_sample_B.u[0];
real_T *y0 = contig_sample_B.timestwoCMEXSFunction_m;
for (i1=0; i1 < 20; i1++) {
y0[i1] = u0[i1] * 2.0;
}
u0 = &contig_sample_B.u_o[0];
y0 = &contig_sample_B.timestwoCMEXSFunction_m[20];
for (i1=0; i1 < 30; i1++) {
y0[i1] = u0[i1] * 2.0;
}
}2 つのループが生成され、それらの間で入力信号が最初のベース アドレス &contig_sample_B.u[0] から信号の 2 つ目のベース アドレス &contig_sample_B.u_o[0] にリダイレクトされていることに注目してください。これを S-Function または生成コードでサポートしないようにする場合は、次を使用できます。
ssSetInputPortRequiredContiguous(S, 1);
これを関数 mdlInitializeSizes で使用すると、バッファー処理を実行するコードが Simulink® で暗黙的に生成されます。このオプションにより、メモリと CPU の両方のサイクルが実行時に余分に使用されますが、バッファーのオーバーヘッドを相殺するほど十分にアルゴリズムのパフォーマンスが向上する場合があります。
ループの生成には %roll 命令を使用します。%roll のリファレンスのエントリについては%roll、%roll の動作の説明については入力信号関数も参照してください。