行優先の配列レイアウトのサブテーブル選択アルゴリズムを含む内挿
この例では、内挿ブロックが次元の大きいテーブルから選択するサブテーブルの内挿のためのアルゴリズムについて説明します。サブテーブル選択を含む内挿アルゴリズムは、行優先の配列レイアウトに最適化されています。参照として、列優先の配列レイアウトに最適化されているサブテーブル選択を含む内挿アルゴリズムを確認します。行優先の内挿アルゴリズムを使用して生成されたコードは、行優先の配列レイアウトのテーブル データを操作する場合に最適な速度とメモリ使用量によるパフォーマンスが得られます。列優先アルゴリズムを使用して生成されたコードは、列優先の配列レイアウトで最適なパフォーマンスが得られます。
この例では次を行います。
列優先アルゴリズムと行優先アルゴリズムを使用して選択されたサブテーブルの内挿。
テーブル置換によるブロック セマンティクスの保持。
行優先アルゴリズムおよび配列レイアウトを使用したコードの生成。
行優先アルゴリズムを使用したシミュレーション
1. モデル例 SubtableInterpolationCol および SubtableInterpolationRow を開きます。
open_system('SubtableInterpolationCol'); open_system('SubtableInterpolationRow');
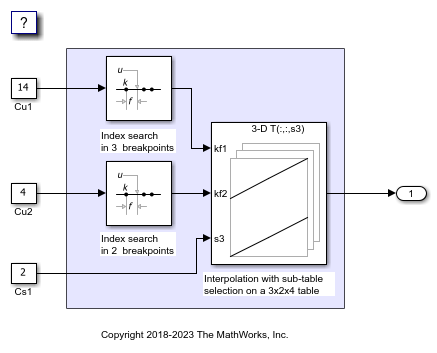
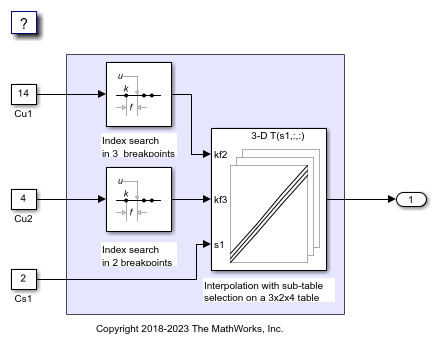
2. Simulink® の既定では、列優先のアルゴリズムおよび列優先の配列レイアウトを使用するモデルが設定されます。モデル SubtableInterpolationCol は列優先アルゴリズムを使用するように設定されています。モデルを実行してワークスペース変数 yout に格納される出力を確認します。
3. 行優先アルゴリズムを有効にするために、[コンフィギュレーション パラメーター] ダイアログ ボックスを開きます。[数学とデータ型] ペインで、コンフィギュレーション パラメーターUse algorithms optimized for row-major array layoutを選択します。あるいは、MATLAB® コマンド ウィンドウで次のように入力します。
set_param('SubtableInterpolationCol','UseRowMajorAlgorithm','on');
4. モデルのシミュレーションを実行してエラーを確認します。

列優先アルゴリズムと行優先アルゴリズムは、サブテーブル選択および内挿順序の観点で異なります。サブテーブル選択は、元のテーブルの内部で行われます。サブテーブルに余分なメモリが割り当てられることはありません。選択されたサブテーブルはメモリ内で連続しています。内挿順序は、列優先の配列レイアウトをもつ列優先アルゴリズムおよび行優先の配列レイアウトをもつ行優先アルゴリズムのキャッシュに対応しています。次の図は、サブテーブル選択を含む行優先の内挿と列優先の内挿を比較します。
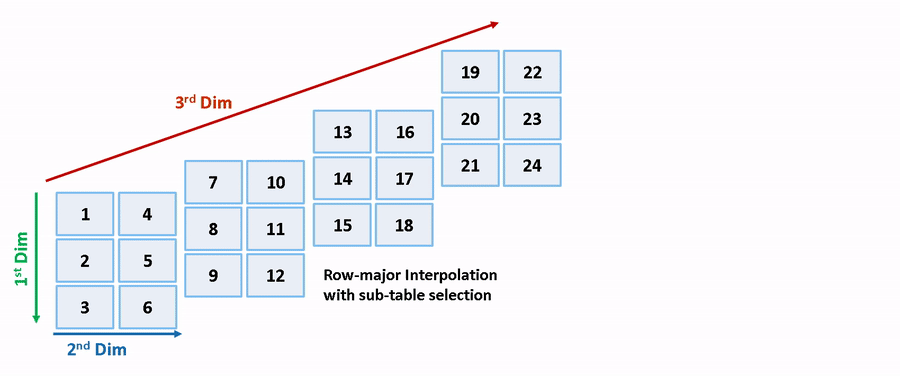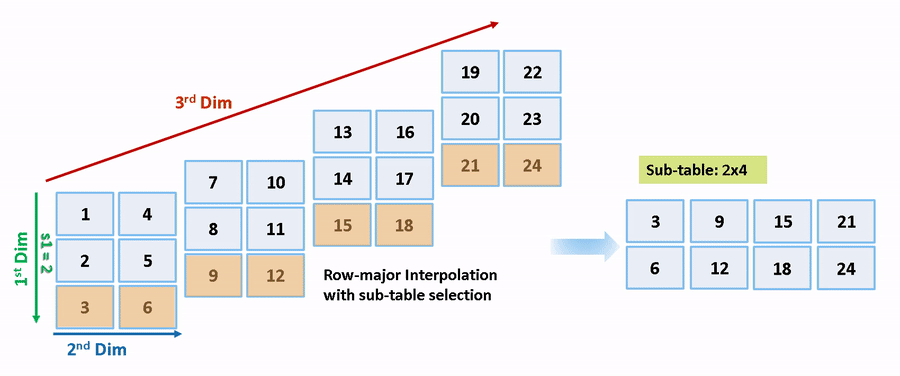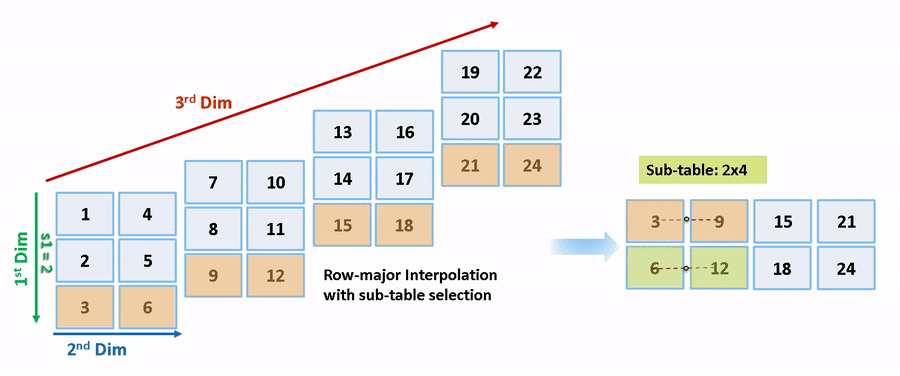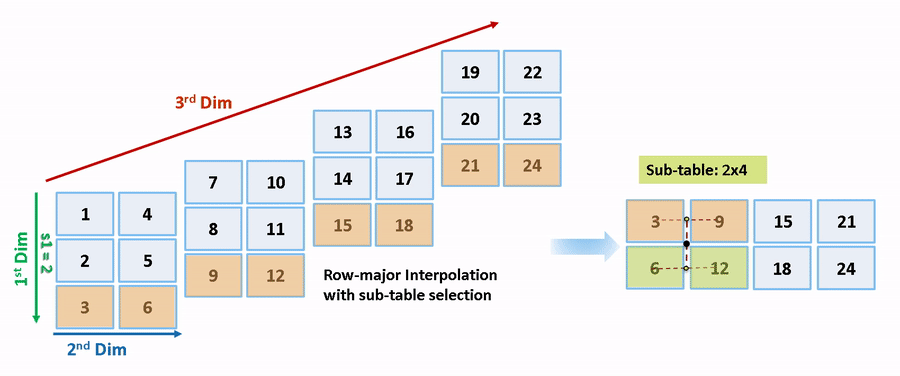
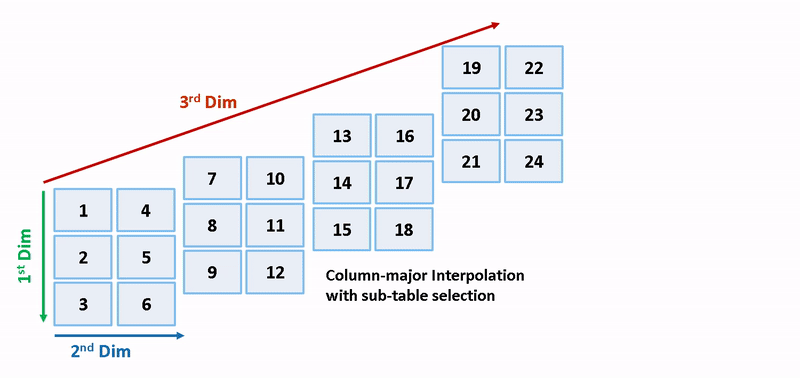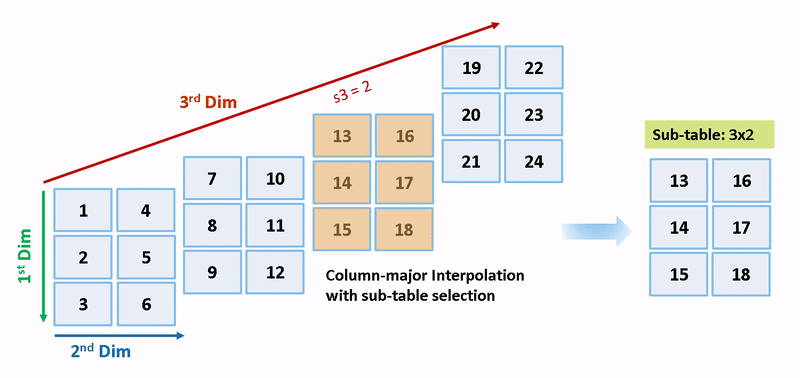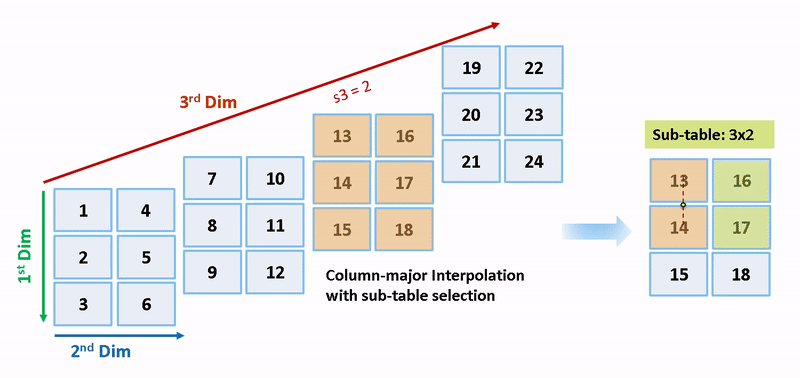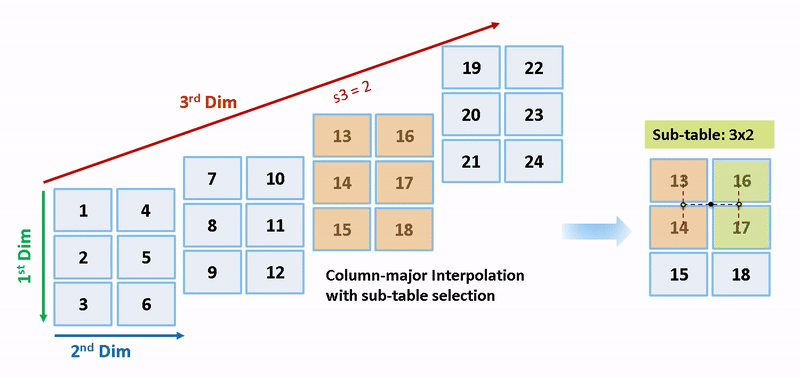
セマンティクスの変更のために、列優先の内挿と行優先の内挿は、異なるサブテーブルまたはデータセットに対して行われます。内挿により、異なる数値の出力やエラーが発生します。
テーブル置換によるセマンティクスの保持
サブテーブル選択を使用すると、列優先アルゴリズムから行優先アルゴリズムに切り替えるときにモデル セマンティクスが変更されます。セマンティクスを保持するか、内挿で同じサブテーブルが必ず選択されるようにするには、テーブル データを置換する必要があります。そうでない場合、Prelookup ブロックと Interpolation ブロックの間に矛盾しているブレークポイントとテーブル データがあると、Simulink がエラーを報告する可能性があります。
1. ブロック SubtableInterpolationCol/Interp には "T3d = reshape([1:24], 3,2,4)" と指定された 3 次元のテーブル データと、入力が "2" (0 ベースのインデックス) の選択端子が 1 つあります。列優先アルゴリズムの選択されたサブテーブルは T3d(:,:,3) (MATLAB は 1 ベースのインデックス) です。同じモデル上の行優先アルゴリズムのセマンティクスを保持するには、同じインデックスおよび選択端子入力をもつ同じサブテーブルを選択し、テーブルを T3d_p = permute(T3d, [3,1,2]) として置換します。行優先アルゴリズムの選択されたサブテーブルは T3d_p(3,:,:) (1 ベースのインデックス) です。
T3d_str = get_param('SubtableInterpolationCol/Interp','Table'); set_param('SubtableInterpolationCol/Interp','Table', ... ['permute(',T3d_str,',[3,1,2])']);
2. テーブル データをファイルからインポートする場合、インポートする前にファイル内のテーブル データを置換しなければなりません。この置換により、テーブルはコード生成ワークフローおよびシミュレーション全体を通じて調整可能なままになります。
行優先アルゴリズムおよび配列レイアウトを使用したコードの生成
テーブル データの置換後に、モデル SubtableInterpolationCol を行優先のシミュレーション向けに構成します。モデルは、行優先アルゴリズムを使用する事前設定されたモデル SubtableInterpolationRow と同じです。
1. モデルを行優先のコード生成用に設定するために、[コンフィギュレーション パラメーター] ダイアログ ボックスを開きます。[行優先の配列レイアウトに最適化されたアルゴリズムを使用] コンフィギュレーション パラメーターの選択に加えて、[コード生成]、[インターフェイス] ペインで、コンフィギュレーション パラメーター配列のレイアウトを [Row-Major] オプションに変更します。このコンフィギュレーション パラメーターにより行優先のコード生成用のモデルが有効になります。あるいは、MATLAB コマンド ウィンドウで次のように入力します。
set_param('SubtableInterpolationCol', 'ArrayLayout','Row-major');
2. ダイアログ ボックスで、置換された 3 次元のテーブル データおよび選択された 2 次元のサブテーブルを調べます。
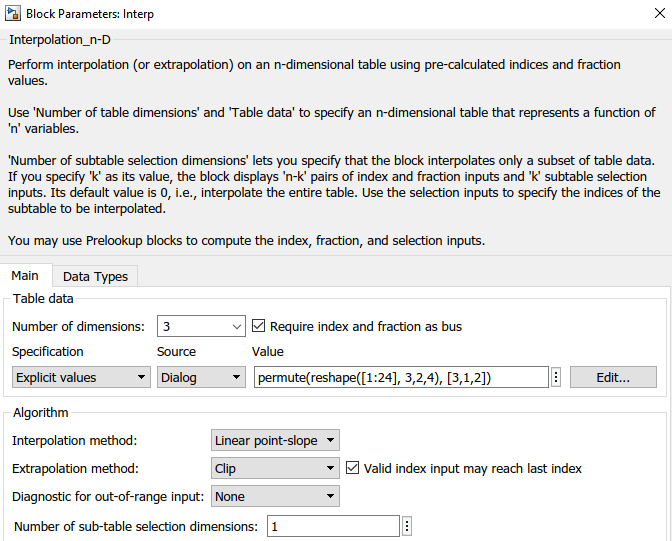
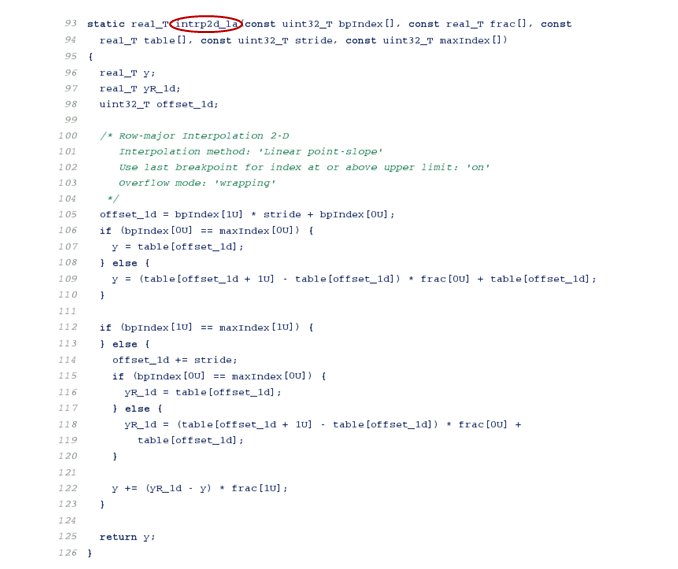
3. MATLAB の現在のフォルダーを書き込み可能なフォルダーに変更します。[C コード] タブで [ビルド] をクリックし、C コードを生成します。生成されたコードで、行優先データに最適化された 2 次元の内挿アルゴリズムを確認します。
close_system('SubtableInterpolationCol',0);