bag of visual words を用いたイメージの分類
Computer Vision Toolbox™ 関数を使用して bag of visual words を作成することで、イメージをカテゴリに分類します。このプロセスにより、イメージを表すビジュアル ワードの出現のヒストグラムが作成されます。これらのヒストグラムを使用して、イメージ カテゴリ分類器の学習を行います。以下の手順では、イメージの設定、bag of visual words の作成、そしてイメージ カテゴリ分類器の学習と適用を行う方法について説明します。
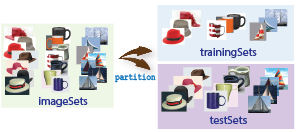
手順 1: イメージ カテゴリのセットの設定
イメージを整理して学習用とテスト用のサブセットに分けます。関数 imageDatastore を使用して、イメージ分類器の学習に使用するイメージを保存します。イメージをカテゴリに整理すると、大量のイメージ セットをより簡単に処理できるようになります。関数 splitEachLabel を使用して、イメージを学習データとテスト データに分割できます。
カテゴリ イメージを読み取ってイメージ セットを作成します。
setDir = fullfile(toolboxdir('vision'),'visiondata','imageSets');
imds = imageDatastore(setDir,'IncludeSubfolders',true,'LabelSource',...
'foldernames');
イメージ セットを学習用のサブセットとテスト用のサブセットに分けます。この例では、イメージの 30% を学習用、残りをテスト用に区分します。
[trainingSet,testSet] = splitEachLabel(imds,0.3,'randomize');
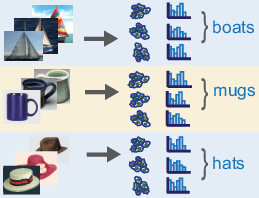
手順 2: bag of features の作成
各カテゴリの典型的なイメージから特徴記述子を抽出して、ビジュアル ボキャブラリ、つまり bag of features を作成します。
bagOfFeatures オブジェクトは、trainingSets から抽出された特徴記述子に対して k-means クラスタリング (Statistics and Machine Learning Toolbox)アルゴリズムを適用し、特徴 (ビジュアル ワード) を定義します。このアルゴリズムは反復して実行され、記述子を k 個の互いに排他的なクラスターにグループ化します。その結果、類似特性によって分類されたコンパクトなクラスターが得られます。各クラスターの中心が特徴、つまりビジュアル ワードを表します。
特徴検出器に基づいて特徴を抽出するか、特徴記述子を抽出するグリッドを定義することができます。グリッドを使用すると、細かいスケールの情報が失われる可能性があります。したがって、グリッドは、海辺などの風景のイメージのように固有の特徴を含まないイメージに使用してください。Speeded Up Robust Features (SURF) 検出器を使用すると、スケールの変化を抑えることができます。既定では、アルゴリズムで 'grid' メソッドが実行されます。

このアルゴリズムのワークフローでは、イメージ全体が解析されます。イメージには、それが表現するクラスを示す適切なラベルが付いていなければなりません。たとえば、自動車のイメージのセットには「自動車」というラベルを付けます。ワークフローはイメージ内の空間情報や、特定オブジェクトのマーキングに依存しません。bag of visual words の手法は、局所化を行わない検出に依存します。
手順 3: bag of visual words を用いたイメージ分類器の学習
関数 trainImageCategoryClassifier は、イメージ分類器を返します。この関数は、誤り訂正出力符号 (ECOC) フレームワークのバイナリ サポート ベクター マシン (SVM) 分類器を使用してマルチクラス分類器の学習を行います。関数 trainImageCategoryClassfier は、bagOfFeatures オブジェクトで返された bag of visual words を使用して、イメージ セットにあるイメージをビジュアル ワードのヒストグラムに符号化します。このビジュアル ワードのヒストグラムが、正およびネガティブ サンプルとして分類器の学習に使用されます。
bagOfFeaturesのencodeメソッドを使用して、学習セットからの各イメージを符号化します。この関数はイメージから特徴を検出して抽出し、適切な最近傍アルゴリズムを使用して各イメージの特徴ヒストグラムを生成します。その後、関数は記述子から特定のクラスター中心までの近さに基づいて、ヒストグラムのビンをインクリメントします。ヒストグラムの長さはbagOfFeaturesオブジェクトが作成したビジュアル ワードの数に対応します。このヒストグラムが、イメージの特徴ベクトルになります。
学習セットの各イメージについて手順 1 を繰り返し、学習データを作成します。
分類器の品質を評価します。
imageCategoryClassifierのevaluateメソッドを使用して、検証イメージ セットに対して分類器をテストします。出力の混同行列は予測の解析を表します。完璧な分類では、対角要素に 1 をもつ正規化された行列が得られます。正しくない分類では、非整数値が得られます。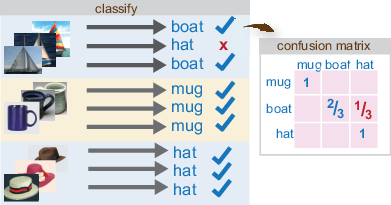
手順 4: イメージまたはイメージ セットの分類
新しいイメージに対して imageCategoryClassifier predict メソッドを使用して、そのカテゴリを判別します。
参照
[1] Csurka, G., C. R. Dance, L. Fan, J. Willamowski, and C. Bray. Visual Categorization with Bags of Keypoints. Workshop on Statistical Learning in Computer Vision. ECCV 1 (1–22), 1–2.
関連するトピック
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)