このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
浅層の多層ニューラル ネットワークの学習と適用
ヒント
深層学習ネットワークに学習させるには、trainnet または trainNetwork を使用します。
このトピックでは、典型的な浅層の多層ネットワークのワークフローの一部について説明します。詳細とその他のステップについては、浅層の多層ニューラル ネットワークと逆伝播学習を参照してください。
ネットワークの重みとバイアスを初期化すると、ネットワークの学習の準備が整います。多層フィードフォワード ネットワークは、関数近似 (非線形回帰) やパターン認識用に学習させることができます。学習プロセスには、適切なネットワーク動作、つまりネットワーク入力 p とターゲット出力 t の例のセットが必要です。
ニューラル ネットワークの学習プロセスでは、ネットワークの重みとバイアスの値が調整されてネットワーク性能が最適化されます。これはネットワーク性能関数 net.performFcn で定義されます。フィードフォワード ネットワークの既定の性能関数は平均二乗誤差 mse です。これは、ネットワーク出力 a とターゲット出力 t の間の平均二乗誤差です。これは、次のように定義されます
(個々の二乗誤差に重み付けすることもできます。誤差の重みを使用したニューラル ネットワークの学習を参照してください)。学習の実装方法には、インクリメンタル モードとバッチ モードの 2 通りがあります。インクリメンタル モードでは、各入力がネットワークに適用されるたびに、勾配が計算されて重みが更新されます。バッチ モードでは、学習セットのすべての入力がネットワークに適用されてから、重みが更新されます。このトピックでは、train コマンドによるバッチ モードでの学習について説明します。adapt コマンドによるインクリメンタル学習はadapt を使用したインクリメンタル学習で説明しています。ほとんどの問題では、Deep Learning Toolbox™ ソフトウェアを使用する場合、インクリメンタル学習よりもバッチ学習の方がかなり高速になり、誤差が小さくなります。
多層フィードフォワード ネットワークの学習では、任意の標準的な数値最適化アルゴリズムを使用して性能関数を最適化できますが、ニューラル ネットワークの学習で優れた性能を示す重要なアルゴリズムがいくつかあります。これらの最適化手法は、ネットワークの重みに対するネットワーク性能の勾配、または重みに対するネットワーク誤差のヤコビアンのいずれかを使用します。
勾配とヤコビアンは、"逆伝播" アルゴリズムと呼ばれる手法で計算されます。この手法では、ネットワークを逆方向にさかのぼって計算が行われます。逆伝播計算は、微積分の連鎖律を使用して導出されます。詳細は、[HDB96] の 11 章 (勾配) と 12 章 (ヤコビアン) を参照してください。
学習アルゴリズム
学習のしくみの例として、最も簡潔な最適化アルゴリズムである勾配降下法を考えます。これは、性能関数が最も早く減少する方向、つまり負の勾配の方向に、ネットワークの重みとバイアスを更新します。このアルゴリズムの 1 反復は、次のように記述できます。
ここで、xk は現在の重みとバイアスのベクトルで、gk は現在の勾配、αk は学習率です。この方程式は、ネットワークが収束するまで反復されます。
Deep Learning Toolbox ソフトウェアで利用でき、勾配ベースまたはヤコビアン ベースの方法を使用する学習アルゴリズムの一覧を、次の表に示します。
これらの手法のいくつかの詳細については、次も参照してください。Hagan, M.T., H.B. Demuth, and M.H. Beale, Neural Network Design, Boston, MA: PWS Publishing, 1996, Chapters 11 and 12.
関数 | アルゴリズム |
|---|---|
レーベンバーグ・マルカート法 | |
ベイズ正則化 | |
BFGS 準ニュートン法 | |
弾性逆伝播法 | |
スケーリング共役勾配法 | |
Powell・Beale リスタート付き共役勾配法 | |
Fletcher・Powell 共役勾配法 | |
Polak・Ribiére 共役勾配法 | |
1 ステップ割線法 | |
可変学習率勾配降下法 | |
モーメンタム項付き勾配降下法 | |
勾配降下法 |
一般的に、最も高速な学習関数は trainlm です。これは feedforwardnet の既定の学習関数です。準ニュートン法の trainbfg もかなり高速です。これらの方法はいずれもメモリと計算時間がより多く必要になるため、大規模ネットワーク (数千個の重みがある場合) にはあまり効率的ではない傾向があります。また、trainlm の性能は、パターン認識問題よりも関数近似 (非線形回帰) 問題に対する方が優れています。
大規模ネットワークの学習時や、パターン認識ネットワークの学習時には、trainscg と trainrp が適しています。これらは必要メモリ量が比較的少ないにもかかわらず、標準の勾配降下法アルゴリズムよりも非常に高速です。
上の表に示した学習アルゴリズムの性能の詳細な比較については、多層ニューラル ネットワークの学習関数の選択を参照してください。
"逆伝播" という用語は、特にニューラル ネットワークの学習に適用する勾配降下法アルゴリズムを指すために使用される場合があることに注意してください。ネットワークを逆方向にさかのぼって計算を行う勾配とヤコビアンの計算プロセスは、上記のすべての学習関数に適用されているため、ここではこの用語を使用していません。使用する具体的な最適化アルゴリズムの名前を使用した方が、逆伝播という用語を単独で使用するよりも明確になります。
多層ネットワークは、逆伝播ネットワークと呼ばれることもあります。しかし、多層ネットワークで勾配とヤコビアンの計算に使用される逆伝播法は、多くの異なるネットワーク アーキテクチャにも適用できます。実際、微分可能な伝達関数、重み関数、および正味入力関数を持つ任意のネットワークの勾配とヤコビアンは、Deep Learning Toolbox ソフトウェアを使用して逆伝播プロセスで計算できます。また、独自のカスタム ネットワークを作成して、上の表にあるいずれかの学習関数を使用して学習させることもできます。勾配とヤコビアンは自動的に計算されます。
学習の例
学習プロセスを説明するために、次のコマンドを実行します。
load bodyfat_dataset
net = feedforwardnet(20);
[net,tr] = train(net,bodyfatInputs,bodyfatTargets);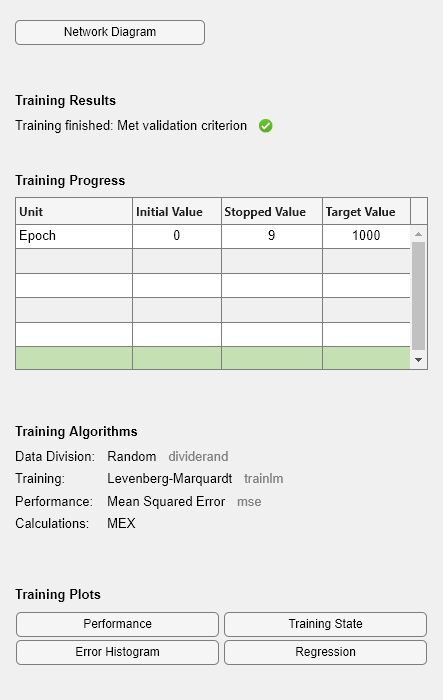
構成は関数 train により自動的に行われるため、configure コマンドを発行する必要がないことに注意してください。次の図に示すように、学習中は学習ウィンドウが表示されます (学習中にこのウィンドウを表示しない場合は、パラメーター net.trainParam.showWindow を false に設定します。学習情報をコマンド ラインで表示するには、パラメーター net.trainParam.showCommandLine を true を設定します)。
このウィンドウには、データが関数 dividerand を使用して分割され、レーベンバーグ・マルカート法 (trainlm) の学習方法が平均二乗誤差の性能関数と共に使用されていることが表示されています。これらは feedforwardnet の既定の設定であることを思い出してください。
学習中は、進行状況が学習ウィンドウに継続的に更新されます。最大の関心は、性能、性能の勾配の大きさ、検証チェックの回数です。勾配の大きさと検証チェックの回数は、学習を終了するために使用されます。学習が性能の最小値に到達すると、勾配は非常に小さくなります。勾配の大きさが 1e-5 未満になると、学習は停止します。この制限は、パラメーター net.trainParam.min_grad を設定することで調整できます。検証チェックの回数は、検証の性能が下がらなかった連続する反復の回数を表します。この数が 6 (既定値) に到達すると、学習は停止します。この実行では、検証チェックの回数が原因で学習が停止したことを確認できます。この条件は、パラメーター net.trainParam.max_fail を設定することで変更できます。(初期の重みとバイアスがランダムに設定されているため、実際の結果は学習の図で示した結果と異なる場合があります。)
ネットワークの学習の停止に使用できる条件は他にもあります。次の表にその一覧を示します。
パラメーター | 停止条件 |
|---|---|
min_grad | 勾配の大きさの最小値 |
max_fail | 検証増分の最大回数 |
time | 学習時間の最大値 |
goal | 性能の最小値 |
epochs | 学習エポック (反復) の最大回数 |
学習ウィンドウの停止ボタンをクリックした場合も、学習は停止します。これは、反復を多数行っても性能関数の値が大幅に下がらない場合に有用です。上で示した train コマンドを再発行することで、いつでも学習を続行できます。前回の実行の完了時点からネットワークの学習が続行されます。
学習ウィンドウから、4 つのプロット (性能、学習の状態、誤差ヒストグラム、回帰) にアクセスできます。性能プロットには、反復回数に対する性能関数の値が表示されます。学習、検証、およびテストの性能がプロットされます。学習の状態のプロットには、勾配の大きさ、検証チェックの回数など、他の学習変数の進行状況が表示されます。誤差ヒストグラムには、ネットワーク誤差の分布が表示されます。回帰プロットには、ネットワーク出力とネットワーク ターゲット間の回帰が表示されます。学習後の浅層ニューラル ネットワークの性能分析で説明するように、ヒストグラム プロットと回帰プロットを使用してネットワーク性能を検証できます。
ネットワークの利用
ネットワークの学習と検証が完了すると、ネットワーク オブジェクトを使用して、任意の入力に対するネットワークの応答を計算できます。たとえば、作成中のデータセットの 5 番目の入力ベクトルに対するネットワーク応答を確認する場合、以下を使用できます。
a = net(bodyfatInputs(:,5))
a = 27.3740
このコマンドを試す場合、ネットワークが初期化されたときの乱数発生器の状態によって出力が異なることがあります。以下では、体脂肪データセットのすべての入力ベクトルの同時実行用セットに対する出力を計算するために、ネットワーク オブジェクトが呼び出されます。これは、すべての入力ベクトルが 1 つの行列に配置されたバッチ モード形式でのシミュレーションです。これは、ベクトルを 1 つずつ与えるよりもはるかに効率的です。
a = net(bodyfatInputs);
ニューラル ネットワークでは、学習を行うたびに異なる解が得られる可能性がありますが、これは初期の重みとバイアスの値が異なり、データの学習セット、検証セット、テスト セットへの分割が異なるためです。このため、別のニューラル ネットワークが同じ問題について学習した場合、入力が同じでも出力が異なる場合があります。ニューラル ネットワークで高い精度が得られるようにするためには、何度か再学習を行います。
高い精度が必要な場合は、初期解を改善するための手法が他にいくつかあります。詳細については、浅層ニューラル ネットワークの汎化の改善と過適合の回避を参照してください。
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)