string 配列を使用したテキスト データの解析
この例では、ファイルのテキストを string 配列として格納し、頻度を基準として単語を並べ替え、結果をプロットして、ファイル内で見つかった単語の基本統計を収集する方法を示します。
string 配列へのテキスト ファイルのインポート
シェイクスピアの『ソネット集』のテキストを関数 fileread で読み取ります。fileread は、テキストを 1 行 100266 列の文字ベクトルとして返します。
sonnets = fileread('sonnets.txt');
sonnets(1:35)ans =
'THE SONNETS
by William Shakespeare'
関数 string を使用して、テキストを string に変換します。次に、関数 splitlines を使用して、改行文字の位置で分割します。sonnets が 2625 行 1 列の string 配列となり、詩の 1 行ずつが各 string に含まれます。sonnets の最初の 5 行を表示します。
sonnets = string(sonnets); sonnets = splitlines(sonnets); sonnets(1:5)
ans = 5x1 string
"THE SONNETS"
""
"by William Shakespeare"
""
""
string 配列の整理
sonnets 内の単語の頻度を計算するには、まず空の string と句読点を削除して整理します。次に、個々の単語を要素として含む string 配列に形状変更します。
string 配列から文字を 1 つも含まない string ("") を削除します。sonnets の各要素を "" (空の string) と比較します。二重引用符を使用して、空の string を含む string を作成できます。TF は logical ベクトルであり、文字が 1 つもない string が sonnets に含まれている場合に true の値を含みます。TF を使用して sonnets にインデックスを付け、文字が 1 つもない文字列をすべて削除します。
TF = (sonnets == "");
sonnets(TF) = [];
sonnets(1:10)ans = 10x1 string
"THE SONNETS"
"by William Shakespeare"
" I"
" From fairest creatures we desire increase,"
" That thereby beauty's rose might never die,"
" But as the riper should by time decease,"
" His tender heir might bear his memory:"
" But thou, contracted to thine own bright eyes,"
" Feed'st thy light's flame with self-substantial fuel,"
" Making a famine where abundance lies,"
一部の句読点を空白文字に置き換えます。たとえば、ピリオド、コンマ、セミコロンを置き換えます。アポストロフィは『ソネット集』の単語の一部をなす可能性があるため (light's など)、残します。
p = [".","?","!",",",";",":"]; sonnets = replace(sonnets,p," "); sonnets(1:10)
ans = 10x1 string
"THE SONNETS"
"by William Shakespeare"
" I"
" From fairest creatures we desire increase "
" That thereby beauty's rose might never die "
" But as the riper should by time decease "
" His tender heir might bear his memory "
" But thou contracted to thine own bright eyes "
" Feed'st thy light's flame with self-substantial fuel "
" Making a famine where abundance lies "
sonnets の各要素から先頭と末尾の空白文字を削除します。
sonnets = strip(sonnets); sonnets(1:10)
ans = 10x1 string
"THE SONNETS"
"by William Shakespeare"
"I"
"From fairest creatures we desire increase"
"That thereby beauty's rose might never die"
"But as the riper should by time decease"
"His tender heir might bear his memory"
"But thou contracted to thine own bright eyes"
"Feed'st thy light's flame with self-substantial fuel"
"Making a famine where abundance lies"
sonnets を、個々の単語を要素として含む string 配列に分割します。関数 split を使用すると、string 配列の要素を空白文字または指定した区切り記号で分割できます。しかし、split では、string 配列の各要素が同数の新しい文字列に分割可能でなければなりません。sonnets の要素に含まれているスペースの数は異なるため、同じ数の文字列に分割することはできません。sonnets で関数 split を使用するには、一度に 1 つの要素に対して split を呼び出す for ループを記述します。
関数 strings を使用して空の string 配列 sonnetWords を作成します。関数 split を使用して sonnets の各要素を分割する for ループを記述します。split からの出力を sonnetWords に連結します。sonnetWords の各要素は sonnets の個々の単語です。
sonnetWords = strings(0); for i = 1:length(sonnets) sonnetWords = [sonnetWords ; split(sonnets(i))]; end sonnetWords(1:10)
ans = 10x1 string
"THE"
"SONNETS"
"by"
"William"
"Shakespeare"
"I"
"From"
"fairest"
"creatures"
"we"
頻度に基づく単語の並べ替え
sonnetWords 内で一意の単語を検索します。単語をカウントし、頻度で並べ替えます。
大文字と小文字の区別だけが異なる単語を同じ単語としてカウントするには、sonnetWords を小文字に変換します。たとえば、The と the は同じ単語としてカウントされます。関数 unique を使用して一意の単語を検索します。次に、関数 histcounts を使用して、一意の単語がそれぞれ出現する回数をカウントします。
sonnetWords = lower(sonnetWords); [words,~,idx] = unique(sonnetWords); numOccurrences = histcounts(idx,numel(words));
sonnetWords 内の単語を、出現数が多い順に並べ替えます。
[rankOfOccurrences,rankIndex] = sort(numOccurrences,'descend');
wordsByFrequency = words(rankIndex);単語の頻度のプロット
『ソネット集』での単語の出現を、多いものから少ないものの順にプロットします。ジップの法則によれば、大規模テキストにおける単語の出現数はべき分布に従います。
loglog(rankOfOccurrences); xlabel('Rank of word (most to least common)'); ylabel('Number of Occurrences');
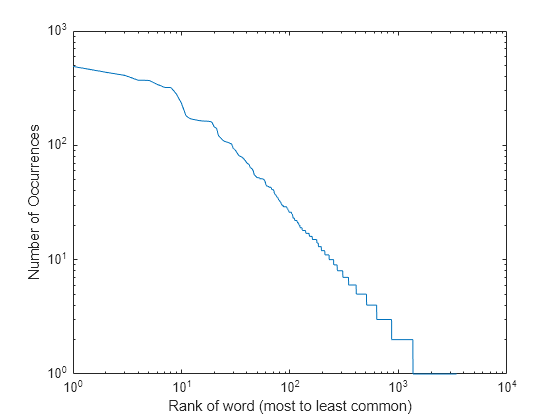
『ソネット集』に最も多く出現する 10 個の単語を表示します。
wordsByFrequency(1:10)
ans = 10x1 string
"and"
"the"
"to"
"my"
"of"
"i"
"in"
"that"
"thy"
"thou"
基本統計を table に集計
sonnetWords 内の各単語の合計出現数を計算します。出現数を単語の総数に対する割合として求め、出現頻度の多い順に累積パーセンテージを計算します。単語とその基本統計を table に書き込みます。
numOccurrences = numOccurrences(rankIndex); numOccurrences = numOccurrences'; numWords = length(sonnetWords); T = table; T.Words = wordsByFrequency; T.NumOccurrences = numOccurrences; T.PercentOfText = numOccurrences / numWords * 100.0; T.CumulativePercentOfText = cumsum(numOccurrences) / numWords * 100.0;
最も多く出現する 10 個の単語の統計を表示します。
T(1:10,:)
ans=10×4 table
Words NumOccurrences PercentOfText CumulativePercentOfText
______ ______________ _____________ _______________________
"and" 490 2.7666 2.7666
"the" 436 2.4617 5.2284
"to" 409 2.3093 7.5377
"my" 371 2.0947 9.6324
"of" 370 2.0891 11.722
"i" 341 1.9254 13.647
"in" 321 1.8124 15.459
"that" 320 1.8068 17.266
"thy" 280 1.5809 18.847
"thou" 233 1.3156 20.163
『ソネット集』に最も多く出現する単語は and で、490 回でした。最も多く出現する 10 個の単語を合わせると、テキストの 20.163% を占めています。
参考
string | split | join | unique | replace | lower | splitlines | histcounts | strip | sort | table
関連するトピック
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)