ttest
1 標本およびペア標本 t 検定
構文
説明
h = ttest(x,y,Name,Value)
h = ttest(x,m,Name,Value)
例
平均がゼロの場合の "t" 検定
標本データを読み込みます。株式収益データの 3 列目を含むベクトルを作成します。
load stockreturns
x = stocks(:,3);標本データが、平均がゼロの母集団から派生しているという帰無仮説を検定します。
[h,p,ci,stats] = ttest(x)
h = 1
p = 0.0106
ci = 2×1
-0.7357
-0.0997
stats = struct with fields:
tstat: -2.6065
df: 99
sd: 1.6027
戻り値 h = 1 は、ttest が有意水準 5% で帰無仮説を棄却することを示します。
さまざまな有意水準における "t" 検定
標本データを読み込みます。株式収益データの 3 列目を含むベクトルを作成します。
load stockreturns
x = stocks(:,3);有意水準 1% において、標本データの派生元は平均がゼロの母集団であるという帰無仮説を検定します。
h = ttest(x,0,'Alpha',0.01)h = 0
戻り値 h = 0 は、ttest が有意水準 1% で帰無仮説を棄却しないことを示します。
ペア標本 "t" 検定
標本データを読み込みます。2 つの試験における学生の採点データを表すデータ行列の 1 列目と 2 列目を含むベクトルを作成します。
load examgrades
x = grades(:,1);
y = grades(:,2);データ ベクトル x と y 間のペアワイズ差分の平均はゼロあるという帰無仮説を検定します。
[h,p] = ttest(x,y)
h = 0
p = 0.9805
h = 0 の戻り値は、ttest が既定の有意水準 5% で帰無仮説を棄却しないことを示します。
さまざまな有意水準におけるペア標本 "t"検定
標本データを読み込みます。2 つの試験における学生の採点データを表すデータ行列の 1 列目と 2 列目を含むベクトルを作成します。
load examgrades
x = grades(:,1);
y = grades(:,2);有意水準 1% において、データ ベクトル x と y 間のペアワイズ差分の平均はゼロであるという帰無仮説を検定します。
[h,p] = ttest(x,y,'Alpha',0.01)h = 0
p = 0.9805
h = 0 の戻り値は、ttest が有意水準 1% で帰無仮説を棄却しないことを示します。
平均を仮定した "t" 検定
標本データを読み込みます。学生の試験採点データの 1 列目が含まれているベクトルを作成します。
load examgrades
x = grades(:,1);標本データの派生元は、平均 m = 75 の分布であるという帰無仮説を検定します。
h = ttest(x,75)
h = 0
h = 0 の戻り値は、ttest が有意水準 5% で帰無仮説を棄却しないことを示します。
片側 "t" 検定
標本データを読み込みます。学生の試験の採点データの 1 列目を含むベクトルを作成します。
load examgrades
x = grades(:,1);試験採点データのヒストグラムをプロットし、正規密度関数を当てはめます。
histfit(x) xlabel("Grade") ylabel("Frequency")
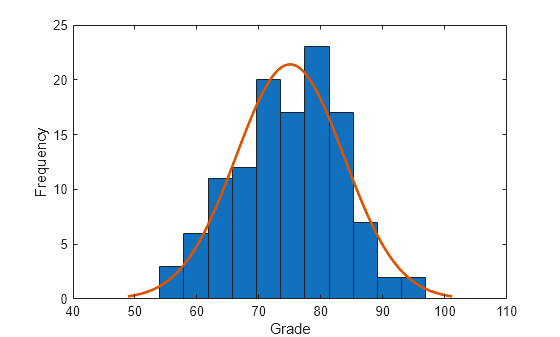
右側 "t" 検定を使用して、データの派生元は、平均が 65 の母集団であるという帰無仮説を、平均が 65 より大きいという対立仮説に対して検定します。
[h,~,~,stats] = ttest(x,65,"Tail","right")
h = 1
stats = struct with fields:
tstat: 12.5726
df: 119
sd: 8.7202
h = 1 の戻り値は、ttest が、平均が 65 より大きい母集団からデータが派生しているという対立仮説を優先して、既定の有意水準 5% で帰無仮説を棄却することを示します。
対応するスチューデントの "t" 分布、返された "t" 統計量、および棄却限界 "t" 値をプロットします。tinv を使用して、既定の信頼水準 95% における棄却限界 "t" 値を計算します。
nu = stats.df; k = linspace(-15,15,300); tdistpdf = tpdf(k,nu); tval = stats.tstat
tval = 12.5726
tvalpdf = tpdf(tval,nu); tcrit = tinv(0.95,nu)
tcrit = 1.6578
plot(k,tdistpdf) hold on scatter(tval,tvalpdf,"filled") xline(tcrit,"--") legend(["Student's t pdf", "t-Statistic", ... "Critical Cutoff"])

オレンジ色のドットは "t" 統計量を表し、棄却限界 "t" 値を表す黒い破線の右側にあります。
入力引数
出力引数
詳細
ヒント
sampsizepwrを使用して以下を計算します。指定された検出力およびパラメーター値に対応する標本サイズ
真のパラメーター値が与えられた場合に特定の標本サイズに対して達成される検出力
指定された標本サイズおよび検出力で検出できるパラメーター値
拡張機能
バージョン履歴
R2006a より前に導入
参考
ztest | ttest2 | sampsizepwr
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)