部分依存プロットを使用した、回帰学習器アプリで学習させた回帰モデルの解釈
学習済みの回帰モデルの場合、部分依存プロット (PDP) は予測子と予測応答の関係を示します。選択した予測子に対する部分依存は、他の予測子の効果を除外することで取得した平均予測によって定義されます。
この例では、回帰学習器アプリで回帰モデルに学習させ、PDP を使用して最適なモデルを解釈する方法を示します。PDP の結果を使用して、モデルで特徴量が予想どおりに使用されることを確認したり、不要な特徴量をモデルの学習から削除したりできます。
MATLAB® コマンド ウィンドウで、
carbigデータ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。load carbig米国製かどうかに基づいて、自動車を分類します。
Origin = categorical(cellstr(Origin)); Origin = mergecats(Origin,["France","Japan","Germany", ... "Sweden","Italy","England"],"NotUSA");
Acceleration、Displacementなどの予測子変数と応答変数MPGが格納された table を作成します。cars = table(Acceleration,Displacement,Horsepower, ... Model_Year,Origin,Weight,MPG);carsから table に欠損値がある行を削除します。cars = rmmissing(cars);
回帰学習器を開きます。[アプリ] タブをクリックしてから、[アプリ] セクションの右にある矢印をクリックしてアプリ ギャラリーを開きます。[機械学習および深層学習] グループの [回帰学習器] をクリックします。
[学習] タブで、[ファイル] セクションの [新規セッション] をクリックし、[ワークスペースから] を選択します。
[ワークスペースからの新規セッション] ダイアログ ボックスで、[データ セット変数] のリストから
[cars]table を選択します。応答変数と予測子変数が選択されます。既定の応答変数は[MPG]です。既定の検証オプションは 5 分割交差検証であるため、過適合が防止されます。[テスト] セクションで、[テスト データ セットの確保] チェック ボックスをクリックします。インポートされたデータの
15パーセントをテスト セットとして指定します。オプションはそのままで続行するため、[セッションの開始] をクリックします。
事前設定されたすべてのモデルに学習させます。[学習] タブの [モデル] セクションで矢印をクリックしてギャラリーを開きます。[開始] グループで [すべて] をクリックします。[学習] セクションで、[すべてを学習] をクリックして [すべてを学習] を選択します。事前設定された各モデル タイプの学習が既定の複雑な木のモデルと共に 1 つずつ行われ、モデルが [モデル] ペインに表示されます。
メモ
Parallel Computing Toolbox™ がある場合は、[並列の使用] ボタンが既定でオンになります。[すべてを学習] をクリックして [すべてを学習] または [選択を学習] を選択すると、ワーカーの並列プールが開きます。この間、ソフトウェアの対話的な操作はできません。プールが開いた後、モデルの学習を並列で実行しながらアプリの操作を続けることができます。
Parallel Computing Toolbox がない場合は、[すべてを学習] メニューの [バックグラウンド学習を使用] チェック ボックスが既定でオンになります。オプションを選択してモデルに学習させると、バックグラウンド プールが開きます。プールが開いた後、モデルの学習をバックグラウンドで実行しながらアプリの操作を続けることができます。
検証平方根平均二乗誤差 (RMSE) に基づいて学習済みモデルを並べ替えます。[モデル] ペインで [並べ替え] リストを開き、
[RMSE (検証)]を選択します。[モデル] ペインで、検証 RMSE 値が最も低いモデルの横にある星形アイコンをクリックします。最も低い検証 RMSE が四角で囲まれて強調表示されます。この例では、学習済みの [Matern 5/2 GPR] モデルの検証 RMSE が最も低くなっています。

メモ
検証により、結果に無作為性が導入されます。実際のモデルの検証結果は、この例に示されている結果と異なる場合があります。
星マークが付いたモデルで、各種のプロット (応答プロット、予測と実際のプロット、残差プロットなど) を使用してモデルの性能をチェックできます。[モデル] ペインでモデルを選択します。[学習] タブの [プロットと結果] セクションで矢印をクリックしてギャラリーを開きます。次に、[検証結果] グループのいずれかのボタンをクリックして対応するプロットを開きます。
複数のプロットを開いた後、モデル プロットのタブの右端にある [ドキュメント アクション] ボタンを使用して、プロットのレイアウトを変更できます。たとえば、ボタンをクリックして
[サブタイル表示]オプションを選択し、レイアウトを指定します。検証プロットの使用方法と表示方法の詳細については、回帰学習器におけるモデルの性能の可視化と評価を参照してください。
元のレイアウトに戻すには、[プロットと結果] セクションで [レイアウト] ボタンをクリックし、[単一モデル (既定)] を選択します。
星マークが付いたモデルで、部分依存プロット (PDP) を使用して、モデルの特徴量とモデル予測の関係を確認します。[説明] タブの [大域的な説明] セクションで [部分依存] をクリックします。PDP では、学習済みモデルの予測応答に対する各予測子の限界効果を可視化できます。アプリによる部分依存の値の計算には、
cars内の観測値のうちテスト用に確保されていない 85% の観測値で学習させたモデルが使用されます。学習データ (つまり、
cars内の観測値の 85%) におけるモデルの予測子とモデル予測の関係を調べます。[データ] で、[学習セット] を選択します。モデル予測に寄与していると思われる特徴量を探します。たとえば、[特徴] で
[Weight]を選択します。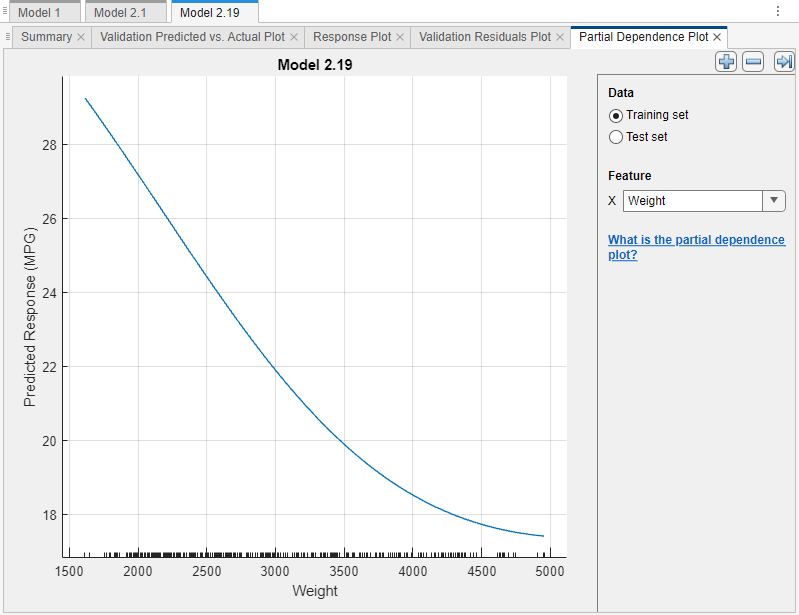
青色でプロットされたラインは、
Weight特徴量と予測されたMPG応答の間の平均化された部分関係性を表します。x 軸の目盛りは、学習データ セット内の一意のWeightの値を示します。このモデル (モデル 2.19) では、MPG (ガロンあたりの走行マイル数) の値は自動車の重量の増加にともなって減少する傾向があります。メモ
一般に、部分依存プロットを解釈する際は値の分布を考慮してください。予測子の値が均等に分布している観測値が十分にある間隔の方が結果の信頼性が高くなる傾向があります。
モデル予測に寄与していないと思われる予測子を削除して、最適なモデルを調整できます。予測応答がすべての予測子の値にわたって一定に維持される PDP は、予測子としては適切でない可能性があります。
この例では、どの予測子の PDP もプロットされたラインは平らではありません。ただし、2 つの予測子
DisplacementおよびHorsepowerが示すモデルの予測応答との関係は、Weight予測子と同様です。[特徴] で、まず
[Displacement]を選択してから[Horsepower]を選択します。

Displacement予測子とHorsepower予測子を最適なモデルから削除します。星マークが付いたモデルのコピーを作成します。[モデル] ペインでモデルを右クリックして [複製] を選択します。次に、モデルの [概要] タブで [特徴選択] セクションを展開し、[Displacement] と [Horsepower] の特徴量の [選択] チェック ボックスをオフにします。

新しいモデルに学習させます。[学習] タブの [学習] セクションで、[すべてを学習] をクリックして [選択を学習] を選択します。
[モデル] ペインで、新しいモデルの横にある星形アイコンをクリックします。星マークが付いたモデルをグループ化するには、[並べ替え] リストを開き、
[お気に入り]を選択します。
特徴量を減らして学習させたモデル (モデル 3) の方が、すべての特徴量を使用して学習させたモデル (モデル 2.19) よりも性能がわずかに高くなっています。
星マークが付いたモデルごとに、テスト セットでモデルの RMSE を計算します。まず、[モデル] ペインでモデルを選択します。次に、[テスト] タブの [テスト] セクションで [選択項目をテスト] をクリックします。
テーブルを使用して、星マークが付いたモデルの検証 RMSE とテスト RMSE の結果を比較します。[テスト] タブの [プロットと結果] セクションで [結果テーブル] をクリックします。[結果テーブル] タブで、テーブルの右上にある [表示する列の選択] ボタンをクリックします。
[表示する列の選択] ダイアログ ボックスで、[事前設定] 列の [選択] ボックスをオンにし、[MSE (検証)]、[決定係数 (検証)]、[MAE (検証)]、[MSE (テスト)]、[決定係数 (テスト)]、[MAE (テスト)] の各列の [選択] チェック ボックスをオフにします。[OK] をクリックします。

この例では、星マークが付いた両方のモデルで、テスト セットにおける性能が良好になっています。
最適なモデルで、テスト データ セットに対する PDP を確認します。部分関係性が予測と一致することを確認します。
この例では、特徴量を減らして学習させたモデルでテスト セットにおける性能が引き続き良好になっているため、このモデル (モデル 3) を選択します。
Acceleration特徴量の学習セットおよびテスト セットの PDP とモデル 3 の予測応答を比較します。[部分依存プロット] タブの [特徴] で、[Acceleration]を選択します。[データ] で、[学習セット] を選択してから [テスト セット] を選択して各プロットを確認します。

PDP のトレンドは学習データ セットとテスト データ セットで同様です。ただし、予測応答値はプロット間でわずかに異なります。この差異の原因としては、学習セットの観測値とテスト セットの観測値の分布の差異が考えられます。
最適なモデルに問題がなければ、学習済みのモデルをワークスペースにエクスポートできます。詳細については、ワークスペースへのモデルのエクスポートを参照してください。回帰学習器で作成したいずれかの部分依存プロットをエクスポートすることもできます。詳細については、回帰学習器アプリのプロットのエクスポートを参照してください。
参考
plotPartialDependence | partialDependence
関連するトピック
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)