このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
groupsummary
グループ要約の計算
構文
説明
テーブル データ
G = groupsummary(___,Name,Value)G = groupsummary(T,"Category1","IncludeMissingGroups",false) は、Category1 の <undefined> で示される categorical 型の欠損データからなるグループを除外します。
配列データ
B = groupsummary(___,Name,Value)
例
入力引数
出力引数
詳細
グループ要約の計算
この表はグループ要約の計算を示します。
サンプル表 T | 構文の例 | 結果の表 |
|---|---|---|
|
| groupsummary(T,"VarA") |
|
groupsummary(T,"VarA","mean") |
| |
groupsummary(T,["VarA" "VarB"],{"none",[-Inf 0 Inf]},"min") |
| |
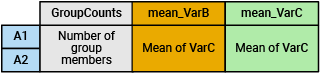
groupsummary(T,"VarA",["mean" "median" "mode"],"VarB") |
|




ヒント
groupsummaryを何度も呼び出す場合、可能であればパフォーマンス向上のためグループ変数をcategorical型またはlogical型に変換することを検討してください。たとえば、string 配列のグループ化変数 (要素が"Poor"、"Fair"、"Good"、"Excellent"であるHealthStatusなど) がある場合、categorical(HealthStatus)コマンドを使用してこれを categorical 変数に変換することができます。関数
groupsummaryは 1 次元の要約統計量を計算します。2 次元のグループ化された要約を計算する場合は、関数pivotの使用を検討してください。
拡張機能
バージョン履歴
R2018a で導入参考
関数
pivot|grouptransform|groupfilter|groupcounts|findgroups|splitapply|discretize|varfun|rowfun|convertvars|vartype
ライブ エディター タスク
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)