このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
複数実験データおよび結合モデルの処理
この例では、System Identification Toolbox™ を使ってモデルを推定および調整するときに、複数実験および結合モデルを処理する方法を説明します。
はじめに
System Identification Toolbox の解析および推定機能を使用すると、複数バッチのデータを処理できます。基本的に、複数の実験を行い、複数の入出力データセットを記録した場合、それらを 1 つの IDDATA オブジェクトにグループ化し、推定ルーチンで使用できます。
場合によっては、(1 つの) 測定データセットを "分割" し、データの質が良くない部分を除去することがあります。たとえば、外乱やセンサー障害のため、一部のデータが使用不能になる場合があります。このような場合、良好なデータ部分を分離し、1 つの複数実験 IDDATA オブジェクトにまとめることができます。
たとえば、データセット iddemo8data.mat を見てみましょう。
load iddemo8dataこのデータ オブジェクトの名前 dat を表示します。
dat
dat =
Time domain data set with 1000 samples.
Sample time: 1 seconds
Outputs Unit (if specified)
y1
Inputs Unit (if specified)
u1
plot(dat)
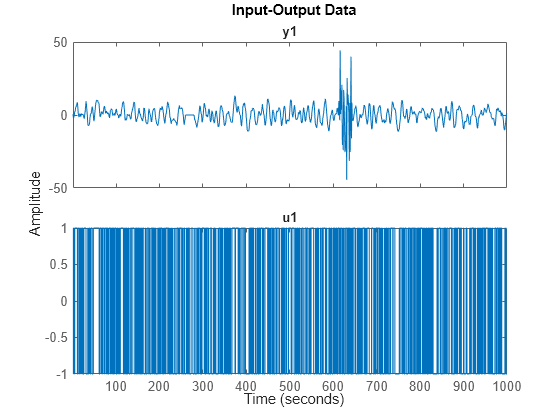
サンプル 250 ~ 280 とサンプル 600 ~ 650 の周辺に問題があることがわかります。これらの問題は、センサー障害と考えられます。
このため、データを 3 つの個別の実験に分割し、それを複数実験データ オブジェクトにします。
d1 = dat(1:250);
d2 = dat(281:600);
d3 = dat(651:1000);
d = merge(d1,d2,d3) % merge lets you create multi-exp IDDATA objectd =
Time domain data set containing 3 experiments.
Experiment Samples Sample Time
Exp1 250 1
Exp2 320 1
Exp3 350 1
Outputs Unit (if specified)
y1
Inputs Unit (if specified)
u1
別々の実験には、たとえば以下のように、別の名前を付けることができます。
d.exp = {'Period 1';'Day 2';'Phase 3'}d =
Time domain data set containing 3 experiments.
Experiment Samples Sample Time
Period 1 250 1
Day 2 320 1
Phase 3 350 1
Outputs Unit (if specified)
y1
Inputs Unit (if specified)
u1
これを確認するには、plot(d) のように plot を使用します。
複数実験データを使用した推定の実行
前述のように、すべてのモデル推定ルーチンは、複数実験データを受け入れ、別々の期間に記録されたものとして評価します。最初の 2 つの実験を推定に、3 番目の実験を検証に使用してみましょう。
de = getexp(d,[1,2]); % subselection is done using the command GETEXP dv = getexp(d,'Phase 3'); % using numbers or names. m1 = arx(de,[2 2 1]); m2 = n4sid(de,2); m3 = armax(de,[2 2 2 1]); compare(dv,m1,m2,m3)
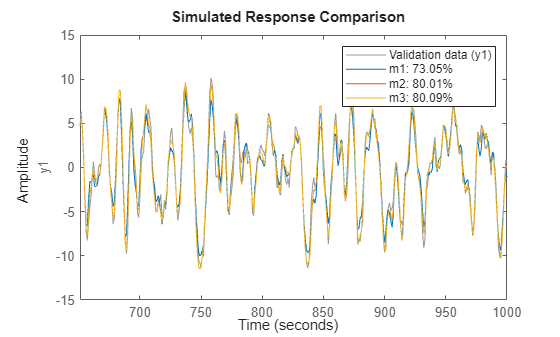
compare コマンドでも複数の実験を受け入れます。右クリック メニューを使用して、使用する実験を一度に 1 つずつ選択します。
compare(d,m1,m2,m3)
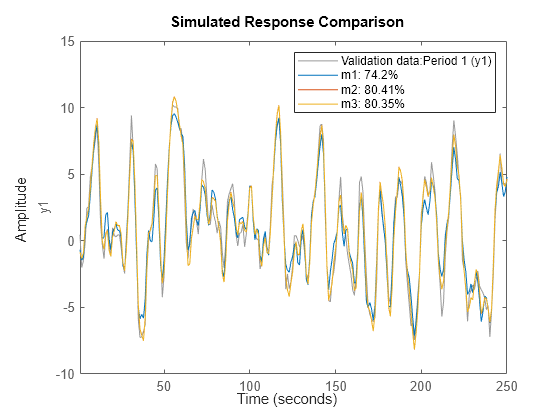
さらに、spa、etfe、resid、predict、sim は、複数実験データについても 1 つの実験データの場合と同じように処理します。
推定後のモデルの結合
個別のデータセットを処理するには、また別の方法があります。各セットにモデルを算出し、これらのモデルを結合する方法です。
m4 = armax(getexp(de,1),[2 2 2 1]);
m5 = armax(getexp(de,2),[2 2 2 1]);
m6 = merge(m4,m5); % m4 and m5 are merged into m6この方法は、結合セット de から m を算出するのと概念的には同じですが、数値的には同じではありません。de での処理では、異なる実験で信号対ノイズ比が (ほぼ) 同じであると想定されますが、個別のモデルを結合した場合、ノイズ レベルは独立した推定を取ります。異なる実験で条件がほぼ同じであれば、複数実験データで直接推定を行いやすくなります。
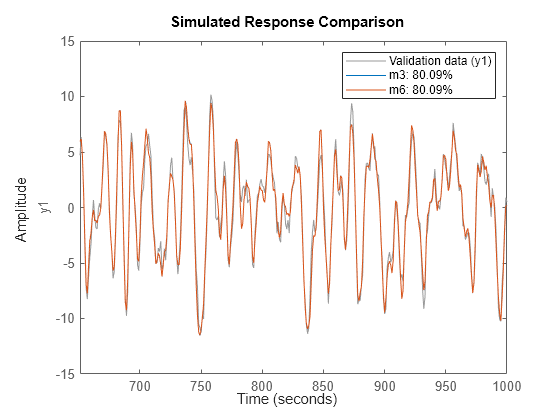
モデル m3 および m6 で確認できます。これらはいずれも、同じデータについて 2 つの異なる方法で取得した ARMAX モデルです。
[m3.a;m6.a]
ans = 2×3
1.0000 -1.5034 0.7008
1.0000 -1.5022 0.7000
[m3.b;m6.b]
ans = 2×3
0 1.0023 0.5029
0 1.0035 0.5028
[m3.c;m6.c]
ans = 2×3
1.0000 -0.9744 0.1578
1.0000 -0.9751 0.1584
compare(dv,m3,m6)
ケース スタディ: 連結と結合の独立したデータセットへの適用
別の状況を考えてみましょう。システム m0 で生成された 2 つのデータセットを使用します。システムは、以下のように指定されます。
m0
m0 =
Discrete-time identified state-space model:
x(t+Ts) = A x(t) + B u(t) + K e(t)
y(t) = C x(t) + D u(t) + e(t)
A =
x1 x2 x3
x1 0.5296 -0.476 0.1238
x2 -0.476 -0.09743 0.1354
x3 0.1238 0.1354 -0.8233
B =
u1 u2
x1 -1.146 -0.03763
x2 1.191 0.3273
x3 0 0
C =
x1 x2 x3
y1 -0.1867 -0.5883 -0.1364
y2 0.7258 0 0.1139
D =
u1 u2
y1 1.067 0
y2 0 0
K =
y1 y2
x1 0 0
x2 0 0
x3 0 0
Sample time: 1 seconds
Parameterization:
STRUCTURED form (some fixed coefficients in A, B, C).
Feedthrough: on some input channels
Disturbance component: none
Number of free coefficients: 23
Use "idssdata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Created by direct construction or transformation. Not estimated.
収集されたデータセットは、z1 と z2 で、異なる入力、ノイズおよび初期条件で m0 から取得されています。これらのデータセットは、先に読み込んだ iddemo8data.mat から取得します。
最初のデータセット:
plot(z1)
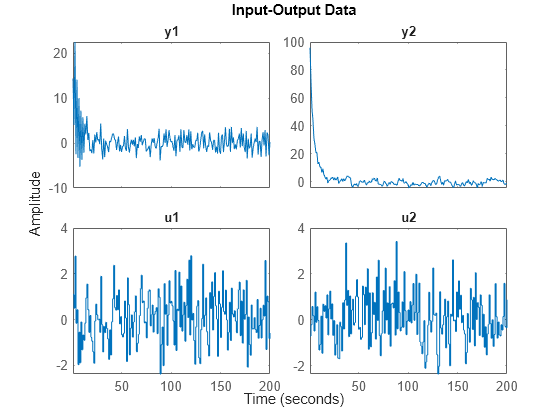
2 番目のデータセット:
plot(z2)
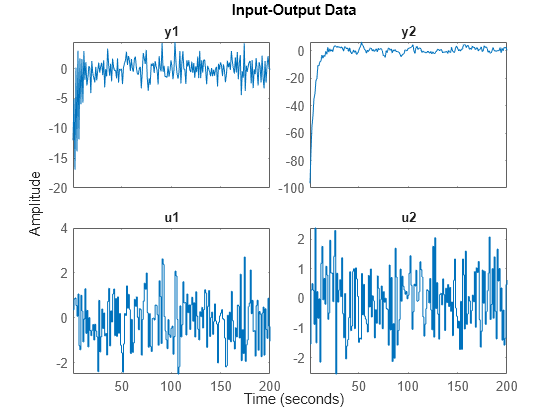
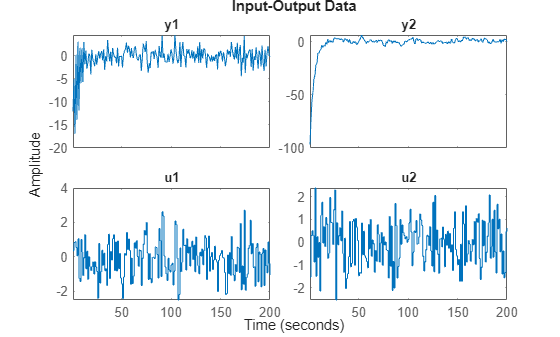
取得したデータを連結するには、以下を行います。
zzl = [z1;z2]
zzl =
Time domain data set with 400 samples.
Sample time: 1 seconds
Outputs Unit (if specified)
y1
y2
Inputs Unit (if specified)
u1
u2
plot(zzl)
離散時間状態空間モデルは ssest を使用して取得できます。
ml = ssest(zzl,3,'Ts',1, 'Feedthrough', [true, false]);
モデル m0 と ml のボード応答を比較します。
clf
bode(m0,ml)
legend('show')
上記の 4 つのボード線図を見ると、これはあまり良好なモデルではありません。
ここで、2 つのデータセットを別々の実験として処理する代わりに、以下を使用します。
zzm = merge(z1,z2)
zzm =
Time domain data set containing 2 experiments.
Experiment Samples Sample Time
Exp1 200 1
Exp2 200 1
Outputs Unit (if specified)
y1
y2
Inputs Unit (if specified)
u1
u2
% The model for this data can be estimated as before (watching progress this time) mm = ssest(zzm,3,'Ts',1,'Feedthrough',[true, false], ssestOptions('Display', 'on'));
Let us compare the Bode plots of the true system (blue)
the model from concatenated data (green) and the model from the
merged data set (red):
clf bode(m0,'b',ml,'g',mm,'r') legend('show')
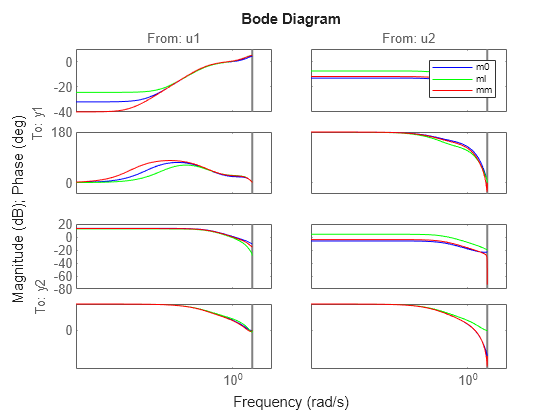
上記のプロットを見るとわかるように、結合データはモデルとしてより優れています。
まとめ
この例では、複数データセットを 1 つのモデルの推定にまとめて使用する方法を解析しました。この手法は、独立した実験から複数のデータセットがある場合や、データを複数セットにセグメント化し、不良セグメントを除去した場合に便利です。複数の実験データは 1 つの IDDATA オブジェクトにパッケージ化し、すべての推定および分析要件で使用できます。この手法は、時間領域と周波数領域の両方の iddata に使用できます。
また、推定の後にモデルを結合することもできます。この手法は、個別に推定されたモデルを "平均化する" ときに使用できます。複数データセットのノイズ特性が異なる場合、推定の後にモデルを結合すると、推定の前にデータセットそのものを結合するよりも良好な結果が得られます。
関連するトピック
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)