ネイティブ浮動小数点のレイテンシに関する考慮事項
HDL Coder™ のネイティブ浮動小数点テクノロジーによって、浮動小数点設計から HDL コードを生成できます。ネイティブ浮動小数点演算子には、レイテンシがあります。HDL コードの生成時、コード ジェネレーターは、このレイテンシを割り出し、対応する遅延を追加することで、並列のパスのバランスを取ります。
浮動小数点演算子のレイテンシの表示
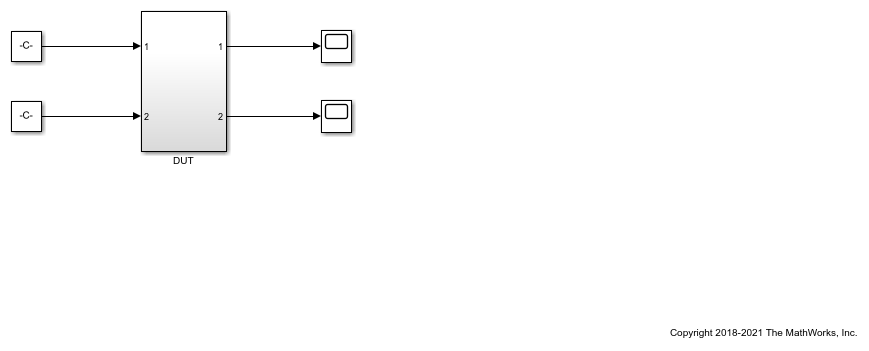
hdlcoder_nfp_delay_allocation Simulink® モデルを開きます。このモデルは、single データ型を使用し、平方根を計算します。コード ジェネレーターが遅延のバランスを取る方法を説明するために、このモデルには並列のパスがあります。
load_system('hdlcoder_nfp_delay_allocation') open_system('hdlcoder_nfp_delay_allocation/DUT')

HDL コードを生成するには、次のようにします。
DUTサブシステムを右クリックし、[HDL コード]、[サブシステムに対する HDL を生成] の順に選択します。HDL コード生成後に、生成されたモデルを確認するには、コマンド ラインで「
gm_hdlcoder_nfp_delay_allocation」と入力します。

NFP sqrt ブロックは、モデル内の Sqrt ブロックに対応する浮動小数点演算子で、レイテンシは 28 です。コード ジェネレーターはこのレイテンシを割り出し、対応する長さ 28 の遅延を並列のパスに追加します。平方根演算のレイテンシを確認するには、NFP Sqrt ブロックをダブルクリックします。Sqrt_pd1 ブロックの [遅延の長さ] は、演算子のレイテンシに対応しています。

設計内のレイテンシはカスタマイズできます。設計にカスタム レイテンシ設定を使用して、レイテンシとスループット間のトレードオフを図ります。その上で、ターゲット FPGA デバイス上の設計の実装を面積と速度について最適化することができます。レイテンシのカスタマイズには、次を利用します。
レイテンシ手法の設定: Simulink モデル全体もしくはモデル内の個々のブロックを、浮動小数点演算子の最大、最小またはゼロのレイテンシにマッピングするかどうかを指定します。
カスタム レイテンシ:Simulink モデル内で使用する特定のブロックに対してカスタム レイテンシを指定できます。カスタム レイテンシ設定は、ゼロから浮動小数点演算子の最大レイテンシの間の値を取ることができます。
オーバーサンプリング係数: [オーバーサンプリング係数] を増加させると、設計は高速のクロック レートで動作し、浮動小数点演算子のレイテンシをもつクロック レート パイプラインを吸収します。
モデル内の Delay ブロック: Simulink モデルにレイテンシが含まれる場合、HDL Coder はネイティブ浮動小数点実装でレイテンシの一部またはすべてを吸収できます。
モデルのレイテンシ手法設定
レイテンシ手法の設定は、モデル全体に対して、またはモデル内のブロックごとに指定できます。
この設定をモデルに対して指定するには、次のようにします。
hdlcoder_nfp_delay_allocationモデルで、DUTサブシステムを右クリックし、[HDL コード]、[HDL Coder プロパティ] を選択します。[HDL コード生成]、[浮動小数点] で [浮動小数点の使用] を選択します。
[レイテンシ手法] で [最大値]、[最小値]、または [ゼロ] を選択します。
コマンド ラインからこの設定を指定するには、次を行います。
1. hdlcoder.createFloatingPointTargetConfig 関数を使用して、ネイティブ浮動小数点用の hdlcoder.FloatingPointTargetConfig オブジェクトを作成します。
nfpconfig = hdlcoder.createFloatingPointTargetConfig("NativeFloatingPoint"); hdlset_param('hdlcoder_nfp_delay_allocation', 'FloatingPointTargetConfiguration', nfpconfig);
2.nfpconfig オブジェクトの LatencyStrategy property を使用して、レイテンシ手法を指定します。
nfpconfig.LibrarySettings.LatencyStrategy = 'MAX'
nfpconfig =
FloatingPointTargetConfig with properties:
Library: 'NATIVEFLOATINGPOINT'
LibrarySettings: [1x1 fpconfig.NFPLatencyDrivenMode]
IPConfig: [1x1 hdlcoder.FloatingPointTargetConfig.IPConfig]
VendorLibrary: []
VendorLibrarySettings: []
VendorIPConfig: []
レイテンシ情報を確認するには、HDL コードを生成してから、生成されたモデルを開きます。生成されたモデルを開くには、コマンド「gm_hdlcoder_nfp_delay_allocation」を入力します。
ブロックのカスタム レイテンシ手法
Simulink モデル内のブロックに対して、レイテンシ手法を選択的にカスタマイズできます。既定では、ブロックはモデルに対して指定するレイテンシ手法設定を継承します。特定のブロックに対しては、カスタム レイテンシ値をゼロから浮動小数点演算子の最大レイテンシの間で指定できます。
カスタム レイテンシを指定することで、次の間のトレードオフ設計をカスタマイズできます。
クロック周波数と電力消費: レイテンシ値が高いと実現可能な最大クロック周波数 (Fmax) が増加し、動的な電力消費が増加します。
オーバーサンプリング係数とサンプリング周波数: 高いレイテンシ値と高いオーバーサンプリング係数を組み合わせることで、実現できる Fmax が増加しますが、サンプリング周波数は減少します。
この設定の詳細と、ブロックのレイテンシ手法を指定する方法については、LatencyStrategyを参照してください。
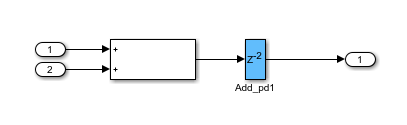
たとえば、モデル内の並列パスに Add ブロックがある場合、次のコマンドを入力することで、その Add ブロックに対してカスタム レイテンシ値 2 を指定できます。
load_system('hdlcoder_nfp_delay_allocation_custom') open_system('hdlcoder_nfp_delay_allocation_custom') hdlset_param('hdlcoder_nfp_delay_allocation_custom/DUT/Add','LatencyStrategy','Custom') hdlset_param('hdlcoder_nfp_delay_allocation_custom/DUT/Add','NFPCustomLatency',2)
レイテンシ情報を確認するには、HDL コードを生成してから、生成されたモデルを開きます。生成されたモデルを開くには、コマンド「gm_hdlcoder_nfp_delay_allocation_custom」を入力します。生成されたモデルで、NFP Add ブロックのレイテンシが 2 であることが分かります。
ネイティブ浮動小数点 IP のカスタム レイテンシ設定
多数の浮動小数点演算子があるモデルでは、NFP 演算子のグローバル カスタム レイテンシを設定して、ネイティブ浮動小数点 IP のレイテンシをカスタマイズできます。カスタマイズはモデル内のすべての演算子に適用されます。
たとえば、モデルに複数の Add ブロックと Product ブロックがある場合、既定では、ブロックはモデルに対して指定されたレイテンシ手法設定を継承します。以下のコマンドを使用して、すべての NFP add ブロックのレイテンシを 4、すべての NFP mul ブロックのレイテンシを 3 にカスタマイズできます。
load_system('hdlcoder_nfp_delay_allocation_global_custom') open_system('hdlcoder_nfp_delay_allocation_global_custom/Sample_DUT'); hdlset_param('hdlcoder_nfp_delay_allocation_global_custom', 'FloatingPointTargetConfiguration', ... hdlcoder.createFloatingPointTargetConfig('NativeFloatingPoint', 'IPConfig', ... {{ 'ADDSUB', 'SINGLE', 'CustomLatency', 4} ... , { 'ADDSUB', 'DOUBLE', 'CustomLatency', 4} ... , { 'MUL', 'SINGLE', 'CustomLatency', 3} ... , { 'MUL', 'DOUBLE', 'CustomLatency', 3}}))
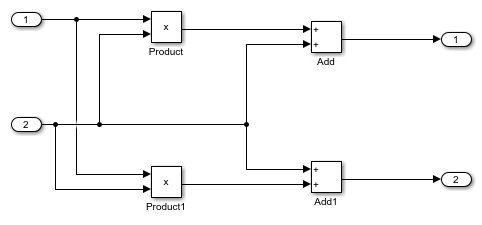
レイテンシ情報を確認するには、HDL コードを生成してから、生成されたモデルを開きます。生成されたモデルを開くには、コマンド「gm_hdlcoder_nfp_delay_allocation_global_custom」を入力します。生成されたモデルで、すべての NFP Add ブロックのレイテンシが 4 であり、すべての NFP mul ブロックのレイテンシが 3 であることがわかります。
コマンドの API でネイティブ浮動小数点 IP に使用するキーワードのリストについては、浮動小数点演算子のレイテンシ値の表を参照してください。
オーバーサンプリング係数
Simulink モデルのブロックをデータ速度で設計する場合は、[オーバーサンプリング係数] に 1 を超える値を指定します。[オーバーサンプリング係数] は、より高速なクロック レートでパイプライン レジスタを挿入して、クロック周波数を改善し、面積の使用率を減らします。クロックレート パイプラインの詳細については、クロックレート パイプラインを参照してください。
[オーバーサンプリング係数] のモデルへの影響を確認するには、hdlcoder_nfp_delay_allocation モデル内で次のようにします。
[遅延の長さ] が
1の Delay ブロックを、Sqrtブロックの出力に追加します。DUT を右クリックし、[HDL コード]、[HDL Coder プロパティ] を選択します。
[HDL コード生成]、[グローバル設定] ペインで、[オーバーサンプリング係数] に値
40を入力します。
HDL コード生成後、生成されたモデルの NFP Sqrt ブロックは、元のモデル内の Sqrt ブロックよりも 40 倍高速なクロック レートで動作していることがわかります。NFP Sqrt ブロックが Simulink モデル内の Delay ブロックを吸収したのです。Delay ブロックは、クロック レートで動作するようになりました。この実装では、追加のレイテンシを吸収することで面積を節約し、高速のクロック レートで動作することでタイミングを改善しています。
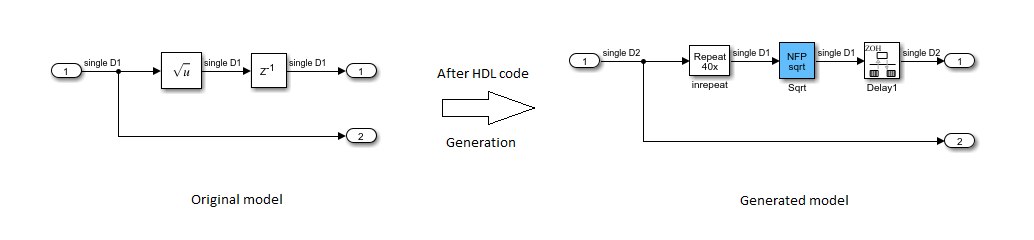
モデル内での遅延吸収
Simulink モデルで十分な [遅延の長さ] をもつ Delay ブロックが演算子に隣接しているか、ゼロ入力を取らず非ゼロの値を出力しないコンポーネント (NOT Logical Operator ブロックなど) のみで演算子と分離されている場合、HDL Coder は演算子レイテンシの一部として遅延を吸収します。
[遅延の長さ] が浮動小数点演算子のレイテンシに等しい場合、HDL Coder が遅延を吸収し、追加のレイテンシは発生しません。
hdlcoder_nfp_delay_allocation モデルで次のようにします。
Sqrt ブロックの出力にある Delay ブロックをダブルクリックし、[遅延の長さ] を
28に変更します。DUTサブシステムの HDL コードを生成します。HDL コード生成後、コマンド ラインで「
gm_hdlcoder_nfp_delay_allocation」と入力し、生成されたモデルを開きます。
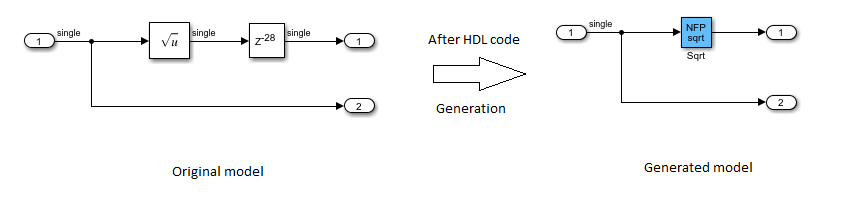
生成されたモデルで、NFP Sqrt ブロックが元のモデルの Sqrt ブロックに隣接する Delay ブロックを吸収したことが分かります。この遅延吸収は、演算子のレイテンシが [遅延の長さ] に等しいために起こります。これにより、コード ジェネレーターは、モデルに追加のレイテンシが発生するのを回避できます。
[遅延の長さ] が演算子のレイテンシ未満の場合、HDL Coder は吸収可能な遅延を吸収し、対応する遅延を追加して、並列のパスとのバランスを取ります。
hdlcoder_nfp_delay_allocation モデルで次のようにします。
Sqrt ブロックの出力にある Delay ブロックをダブルクリックし、[遅延の長さ] を
21に変更します。DUTサブシステムの HDL コードを生成します。HDL コード生成後、コマンド ラインで「
gm_hdlcoder_nfp_delay_allocation」と入力し、生成されたモデルを開きます。

NFP Sqrt ブロックが遅延の長さ 21 を吸収し、平方根演算には 28 の遅延が必要なことから、対応する長さ 7 の遅延が並列パスに追加されたことが分かります。
遅延の長さが演算子のレイテンシを超える場合、コード ジェネレーターは、レイテンシに等しい分の遅延を吸収し、余った遅延は演算子の外側に現れます。
hdlcoder_nfp_delay_allocation モデルで次のようにします。
Sqrt ブロックの出力にある Delay ブロックをダブルクリックし、[遅延の長さ] を
34に変更します。DUTサブシステムの HDL コードを生成します。HDL コード生成後、コマンド ラインで「
gm_hdlcoder_nfp_delay_allocation」と入力し、生成されたモデルを開きます。
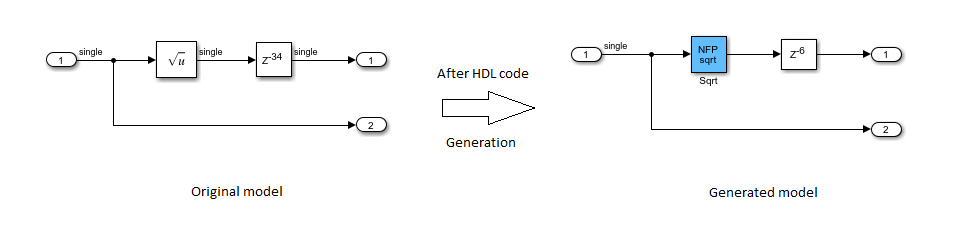
平方根演算のレイテンシは 28 であることから、NFP Sqrt ブロックは遅延 28 を吸収しました。余ったレイテンシ 6 は、演算子の外側にあります。
参考
モデリング ガイドライン
関数
関連する例
詳細
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)