このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
GPU Coder を使用した線形システム求解のベンチマーク
この例では、CUDA® コードを生成することによって、線形システム求解のベンチマークを行う方法を示します。行列の左除算 (mldivideまたはバックスラッシュ演算子 (\) とも呼ばれる) を使用して、線形方程式系 A*x = b を x について解きます (つまり、x = A\b を計算します)。
サードパーティの必要条件
必須
この例では、CUDA MEX を生成します。以下のサードパーティ要件が適用されます。
CUDA 対応 NVIDIA® GPU および互換性のあるドライバー。
オプション
スタティック ライブラリ、ダイナミック ライブラリ、または実行可能ファイルなどの MEX 以外のビルドについて、この例では以下の要件も適用されます。
NVIDIA Toolkit。
コンパイラおよびライブラリの環境変数。詳細については、サードパーティ ハードウェアと前提条件となる製品の設定を参照してください。
GPU 環境の検証
この例を実行するのに必要なコンパイラおよびライブラリが正しく設定されていることを検証するために、関数coder.checkGpuInstallを使用します。
envCfg = coder.gpuEnvConfig('host');
envCfg.BasicCodegen = 1;
envCfg.Quiet = 1;
coder.checkGpuInstall(envCfg);最大データ サイズの決定
CPU および GPU で利用できるシステム メモリの量を GB 単位で指定して、計算に適切な行列のサイズを選択します。既定値は GPU で利用できるメモリの量のみに基づきます。システムに適切な値を指定することができます。
g = gpuDevice; maxMemory = 0.1*g.AvailableMemory/1024^3;
メモ:
この例では、ワークスペースを作成するために大容量の GPU メモリを必要とする cuSOLVER ライブラリを使用します。CUDA のメモリ不足エラーが発生した場合は、maxMemory を減らすか、sizeSingle と sizeDouble の行列のステップ サイズを減らしてください。
ベンチマーク関数
この例では、CPU と GPU の間でのデータ転送コストを含む、GPU Coder™ 使用時の全体的なアプリケーションの時間を明確に把握するために、行列の左除算 (\) のベンチマークを実行します。アプリケーション時間のプロファイリングには、サンプル入力データを作成するための時間を含めてはなりません。関数 genData.m は、線形システムを解くエントリポイント関数からテスト データの生成を分離します。
type getData.mfunction [A, b] = getData(n, clz)
% Copyright 2017-2022 The MathWorks, Inc.
fprintf('Creating a matrix of size %d-by-%d.\n', n, n);
A = rand(n, n, clz) + 100*eye(n, n, clz);
b = rand(n, 1, clz);
end
バックスラッシュ エントリポイント関数
backslash.m エントリポイント関数は、コードを生成する (\) 演算をカプセル化します。
type backslash.mfunction [x] = backslash(A,b)
%#codegen
% Copyright 2017-2022 The MathWorks, Inc.
coder.gpu.kernelfun();
x = A\b;
end
GPU コードの生成
特定の入力データ サイズに基づいて GPU MEX 関数を生成する関数を作成します。
type genGpuCode.mfunction [] = genGpuCode(A, b)
% Copyright 2017-2022 The MathWorks, Inc.
cfg = coder.gpuConfig('mex');
evalc('codegen -config cfg -args {A,b} backslash');
end
問題サイズの選択
線形システムを解く並列アルゴリズムのパフォーマンスは、行列のサイズに大きく左右されます。この例では、さまざまな行列のサイズ (1024 の倍数) についてアルゴリズムのパフォーマンスを比較します。
sizeLimit = inf; if ispc sizeLimit = double(intmax('int32')); end maxSizeSingle = min(floor(sqrt(maxMemory*1024^3/4)),floor(sqrt(sizeLimit/4))); maxSizeDouble = min(floor(sqrt(maxMemory*1024^3/8)),floor(sqrt(sizeLimit/8))); step = 1024; if maxSizeDouble/step >= 10 step = step*floor(maxSizeDouble/(5*step)); end sizeSingle = 1024:step:maxSizeSingle; sizeDouble = 1024:step:maxSizeDouble; numReps = 5;
パフォーマンスの比較: 高速化
合計経過時間をパフォーマンスの測定基準として使用します。そうすることで、さまざまな行列のサイズについてアルゴリズムのパフォーマンスを比較できるためです。行列のサイズを与えると、ベンチマーク関数は行列 A と右辺 b を 1 回作成し、A\b を数回解くことでそれに要した正確な時間を測定します。
type benchFcnMat.mfunction time = benchFcnMat(A, b, reps)
% Copyright 2017-2022 The MathWorks, Inc.
time = inf;
% Solve the linear system a few times and take the best run
for itr = 1:reps
tic;
matX = backslash(A, b);
tcurr = toc;
time = min(tcurr, time);
end
end
生成された GPU MEX 関数を呼び出す GPU コード実行用の別の関数を作成します。
type benchFcnGpu.mfunction time = benchFcnGpu(A, b, reps)
% Copyright 2017-2022 The MathWorks, Inc.
time = inf;
gpuX = backslash_mex(A, b);
for itr = 1:reps
tic;
gpuX = backslash_mex(A, b);
tcurr = toc;
time = min(tcurr, time);
end
end
ベンチマークの実行
ベンチマークを実行する場合、計算が完了するまでに長い時間がかかる可能性があります。各行列のサイズについてのベンチマークの完了時に、一部の中間ステータス情報を出力します。単精度および倍精度の計算についてベンチマークを実行するために、すべての行列のサイズに対するループを関数にカプセル化します。
実際の実行時間はハードウェア構成によって異なる可能性があります。このベンチマークは、6 コアの 3.5 GHz Intel® Xeon® CPU および NVIDIA TITAN Xp GPU を搭載したマシンで MATLAB R2022a を使用して行われました。
type executeBenchmarks.mfunction [timeCPU, timeGPU] = executeBenchmarks(clz, sizes, reps)
% Copyright 2017-2022 The MathWorks, Inc.
fprintf(['Starting benchmarks with %d different %s-precision ' ...
'matrices of sizes\nranging from %d-by-%d to %d-by-%d.\n'], ...
length(sizes), clz, sizes(1), sizes(1), sizes(end), ...
sizes(end));
timeGPU = zeros(size(sizes));
timeCPU = zeros(size(sizes));
for i = 1:length(sizes)
n = sizes(i);
fprintf('Size : %d\n', n);
[A, b] = getData(n, clz);
genGpuCode(A, b);
timeCPU(i) = benchFcnMat(A, b, reps);
fprintf('Time on CPU: %f sec\n', timeCPU(i));
timeGPU(i) = benchFcnGpu(A, b, reps);
fprintf('Time on GPU: %f sec\n', timeGPU(i));
fprintf('\n');
end
end
単精度および倍精度でベンチマークを実行します。
[cpu, gpu] = executeBenchmarks('single', sizeSingle, numReps);Starting benchmarks with 9 different single-precision matrices of sizes ranging from 1024-by-1024 to 17408-by-17408. Size : 1024 Creating a matrix of size 1024-by-1024. Time on CPU: 0.012281 sec Time on GPU: 0.008329 sec Size : 3072 Creating a matrix of size 3072-by-3072. Time on CPU: 0.115839 sec Time on GPU: 0.035071 sec Size : 5120 Creating a matrix of size 5120-by-5120. Time on CPU: 0.380651 sec Time on GPU: 0.074228 sec Size : 7168 Creating a matrix of size 7168-by-7168. Time on CPU: 0.867239 sec Time on GPU: 0.127977 sec Size : 9216 Creating a matrix of size 9216-by-9216. Time on CPU: 1.677065 sec Time on GPU: 0.205344 sec Size : 11264 Creating a matrix of size 11264-by-11264. Time on CPU: 2.911081 sec Time on GPU: 0.306867 sec Size : 13312 Creating a matrix of size 13312-by-13312. Time on CPU: 4.684644 sec Time on GPU: 0.440095 sec Size : 15360 Creating a matrix of size 15360-by-15360. Time on CPU: 6.950956 sec Time on GPU: 0.608897 sec Size : 17408 Creating a matrix of size 17408-by-17408. Time on CPU: 9.833478 sec Time on GPU: 0.802604 sec
results.sizeSingle = sizeSingle;
results.timeSingleCPU = cpu;
results.timeSingleGPU = gpu;
[cpu, gpu] = executeBenchmarks('double', sizeDouble, numReps);Starting benchmarks with 6 different double-precision matrices of sizes ranging from 1024-by-1024 to 11264-by-11264. Size : 1024 Creating a matrix of size 1024-by-1024. Time on CPU: 0.021463 sec Time on GPU: 0.010796 sec Size : 3072 Creating a matrix of size 3072-by-3072. Time on CPU: 0.213805 sec Time on GPU: 0.093114 sec Size : 5120 Creating a matrix of size 5120-by-5120. Time on CPU: 0.689023 sec Time on GPU: 0.323026 sec Size : 7168 Creating a matrix of size 7168-by-7168. Time on CPU: 1.687437 sec Time on GPU: 0.775834 sec Size : 9216 Creating a matrix of size 9216-by-9216. Time on CPU: 3.521580 sec Time on GPU: 1.539601 sec Size : 11264 Creating a matrix of size 11264-by-11264. Time on CPU: 6.075310 sec Time on GPU: 2.694465 sec
results.sizeDouble = sizeDouble; results.timeDoubleCPU = cpu; results.timeDoubleGPU = gpu;
パフォーマンスのプロット
結果をプロットし、単精度および倍精度についての CPU および GPU のパフォーマンスを比較します。
まず、単精度のバックスラッシュ演算子のパフォーマンスを確認します。
fig = figure; ax = axes('parent', fig); plot(ax, results.sizeSingle, results.timeSingleGPU, '-x', ... results.sizeSingle, results.timeSingleCPU, '-o') grid on; legend('GPU', 'CPU', 'Location', 'NorthWest'); title(ax, 'Single-Precision Performance') ylabel(ax, 'Time (s)'); xlabel(ax, 'Matrix Size');
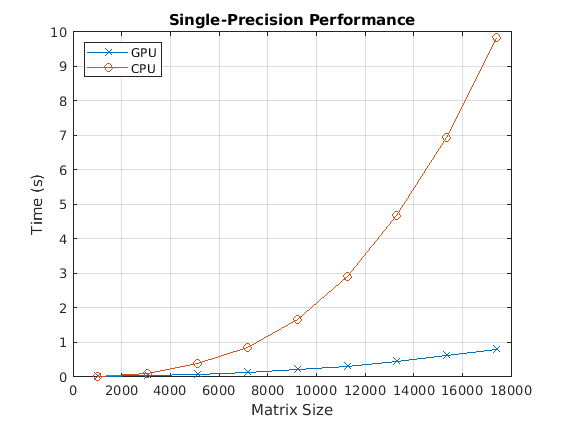
drawnow;
次に、倍精度のバックスラッシュ演算子のパフォーマンスを確認します。
fig = figure; ax = axes('parent', fig); plot(ax, results.sizeDouble, results.timeDoubleGPU, '-x', ... results.sizeDouble, results.timeDoubleCPU, '-o') legend('GPU', 'CPU', 'Location', 'NorthWest'); grid on; title(ax, 'Double-Precision Performance') ylabel(ax, 'Time (s)'); xlabel(ax, 'Matrix Size'); drawnow;
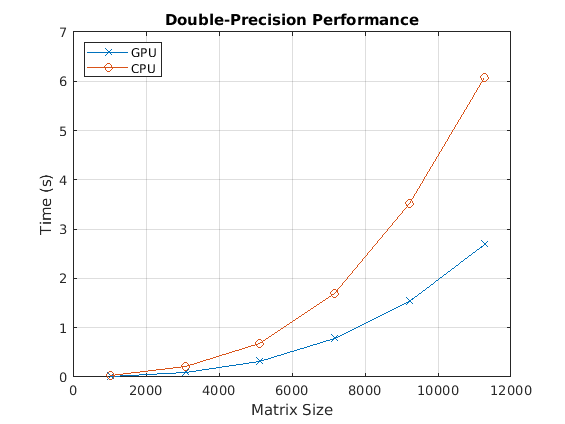
最後に、GPU と CPU を比較したときのバックスラッシュ演算子の高速化を確認します。
speedupDouble = results.timeDoubleCPU./results.timeDoubleGPU; speedupSingle = results.timeSingleCPU./results.timeSingleGPU; fig = figure; ax = axes('parent', fig); plot(ax, results.sizeSingle, speedupSingle, '-v', ... results.sizeDouble, speedupDouble, '-*') grid on; legend('Single-precision', 'Double-precision', 'Location', 'SouthEast'); title(ax, 'Speedup of Computations on GPU Compared to CPU'); ylabel(ax, 'Speedup'); xlabel(ax, 'Matrix Size'); drawnow;

参考
関数
codegen|coder.gpu.kernel|coder.gpu.kernelfun|gpucoder.matrixMatrixKernel|coder.gpu.constantMemory|gpucoder.stencilKernel|coder.checkGpuInstall
オブジェクト
関連するトピック
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)