このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
sequenceInputLayer
シーケンス入力層
説明
シーケンス入力層は、シーケンス データをニューラル ネットワークに入力し、データ正規化を適用します。
作成
プロパティ
例
シーケンス入力層の作成
名前が 'seq1'、入力サイズが 12 のシーケンス入力層を作成します。
layer = sequenceInputLayer(12,'Name','seq1')
layer =
SequenceInputLayer with properties:
Name: 'seq1'
InputSize: 12
MinLength: 1
SplitComplexInputs: 0
Hyperparameters
Normalization: 'none'
NormalizationDimension: 'auto'
シーケンス入力層を Layer 配列に含めます。
inputSize = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(inputSize) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer]
layers =
5x1 Layer array with layers:
1 '' Sequence Input Sequence input with 12 dimensions
2 '' LSTM LSTM with 100 hidden units
3 '' Fully Connected 9 fully connected layer
4 '' Softmax softmax
5 '' Classification Output crossentropyex
イメージ シーケンスのシーケンス入力層の作成
名前が 'seq1' の 224 行 224 列の RGB イメージのシーケンスに対して、シーケンス入力層を作成します。
layer = sequenceInputLayer([224 224 3], 'Name', 'seq1')
layer =
SequenceInputLayer with properties:
Name: 'seq1'
InputSize: [224 224 3]
MinLength: 1
SplitComplexInputs: 0
Hyperparameters
Normalization: 'none'
NormalizationDimension: 'auto'
シーケンス分類についてのネットワークの学習
sequence-to-label 分類について深層学習 LSTM ネットワークに学習をさせます。
サンプル データを WaveformData.mat から読み込みます。データは、numObservations 行 1 列のシーケンスの cell 配列です。ここで、numObservations はシーケンスの数です。各シーケンスは numChannels 行 -numTimeSteps 列の数値配列です。ここで、numChannels はシーケンスのチャネル数、numTimeSteps はシーケンスのタイム ステップ数です。
load WaveformDataシーケンスの一部をプロットで可視化します。
numChannels = size(data{1},1);
idx = [3 4 5 12];
figure
tiledlayout(2,2)
for i = 1:4
nexttile
stackedplot(data{idx(i)}',DisplayLabels="Channel "+string(1:numChannels))
xlabel("Time Step")
title("Class: " + string(labels(idx(i))))
end
テスト用のデータを確保します。データの 90% から成る学習セットとデータの残りの 10% から成るテスト セットにデータを分割します。データを分割するには、この例にサポート ファイルとして添付されている関数 trainingPartitions を使用します。このファイルにアクセスするには、例をライブ スクリプトとして開きます。
numObservations = numel(data); [idxTrain,idxTest] = trainingPartitions(numObservations, [0.9 0.1]); XTrain = data(idxTrain); TTrain = labels(idxTrain); XTest = data(idxTest); TTest = labels(idxTest);
LSTM ネットワーク アーキテクチャを定義します。入力サイズを入力データのチャネルの数として指定します。120 個の隠れユニットを含み、シーケンスの最後の要素を出力するように LSTM 層を指定します。最後に、クラス数と一致する出力サイズをもつ全結合層を含め、その後にソフトマックス層と分類層を含めます。
numHiddenUnits = 120; numClasses = numel(categories(TTrain)); layers = [ ... sequenceInputLayer(numChannels) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer classificationLayer]
layers =
5×1 Layer array with layers:
1 '' Sequence Input Sequence input with 3 dimensions
2 '' LSTM LSTM with 120 hidden units
3 '' Fully Connected 4 fully connected layer
4 '' Softmax softmax
5 '' Classification Output crossentropyex
学習オプションを指定します。学習率 0.01、勾配しきい値 1 で Adam ソルバーを使用して学習させます。エポックの最大数を 150 に設定し、すべてのエポックでデータをシャッフルします。既定では、ソフトウェアは GPU が利用できる場合に GPU で学習を行います。GPU を使用するには、Parallel Computing Toolbox とサポートされている GPU デバイスが必要です。サポートされているデバイスについては、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。
options = trainingOptions("adam", ... MaxEpochs=150, ... InitialLearnRate=0.01,... Shuffle="every-epoch", ... GradientThreshold=1, ... Verbose=false, ... Plots="training-progress");
学習オプションを指定して LSTM ネットワークに学習させます。
net = trainNetwork(XTrain,TTrain,layers,options);

テスト データを分類します。学習に使用されるサイズと同じミニバッチ サイズを指定します。
YTest = classify(net,XTest);
予測の分類精度を計算します。
acc = mean(YTest == TTest)
acc = 0.8400
分類結果を混同チャートで表示します。
figure confusionchart(TTest,YTest)

分類用の LSTM ネットワーク
sequence-to-label 分類用の LSTM ネットワークを作成するには、シーケンス入力層、LSTM 層、全結合層、ソフトマックス層、および分類出力層を含む層配列を作成します。
シーケンス入力層のサイズを入力データの特徴の数に設定します。全結合層のサイズをクラスの数に設定します。シーケンス長を指定する必要はありません。
LSTM 層では、隠れユニットの数と出力モード 'last' を指定します。
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
sequence-to-label 分類について LSTM ネットワークに学習をさせ、新しいデータを分類する方法の例については、深層学習を使用したシーケンスの分類を参照してください。
sequence-to-sequence 分類用の LSTM ネットワークを作成するには、sequence-to-label 分類の場合と同じアーキテクチャを使用しますが、LSTM 層の出力モードを 'sequence' に設定します。
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
回帰用の LSTM ネットワーク
sequence-to-one 回帰用の LSTM ネットワークを作成するには、シーケンス入力層、LSTM 層、全結合層、および回帰出力層を含む層配列を作成します。
シーケンス入力層のサイズを入力データの特徴の数に設定します。全結合層のサイズを応答の数に設定します。シーケンス長を指定する必要はありません。
LSTM 層では、隠れユニットの数と出力モード 'last' を指定します。
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numResponses) regressionLayer];
sequence-to-sequence 回帰用の LSTM ネットワークを作成するには、sequence-to-one 回帰の場合と同じアーキテクチャを使用しますが、LSTM 層の出力モードを 'sequence' に設定します。
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numResponses) regressionLayer];
sequence-to-sequence 回帰について LSTM ネットワークに学習をさせて、新しいデータを予測する方法の例については、深層学習を使用した sequence-to-sequence 回帰を参照してください。
深い LSTM ネットワーク
出力モードが 'sequence' の追加の LSTM 層を LSTM 層の前に挿入すると、LSTM ネットワークを深くできます。過適合を防止するために、LSTM 層の後にドロップアウト層を挿入できます。
sequence-to-label 分類ネットワークでは、最後の LSTM 層の出力モードは 'last' でなければなりません。
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','last') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
sequence-to-sequence 分類ネットワークでは、最後の LSTM 層の出力モードは 'sequence' でなければなりません。
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','sequence') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
ビデオ分類用のネットワークの作成
ビデオや医用画像データなどのイメージのシーケンスを含むデータ用の深層学習ネットワークを作成します。
イメージのシーケンスをネットワークに入力するには、シーケンス入力層を使用します。
畳み込み演算を各タイム ステップに個別に適用するには、まずシーケンス折りたたみ層を使用してイメージのシーケンスをイメージの配列に変換します。
これらの演算の実行後にシーケンス構造を復元するには、シーケンス展開層を使用してこのイメージの配列をイメージ シーケンスに変換し直します。
イメージを特徴ベクトルに変換するには、フラット化層を使用します。
その後、ベクトル シーケンスを LSTM 層と BiLSTM 層に入力できます。
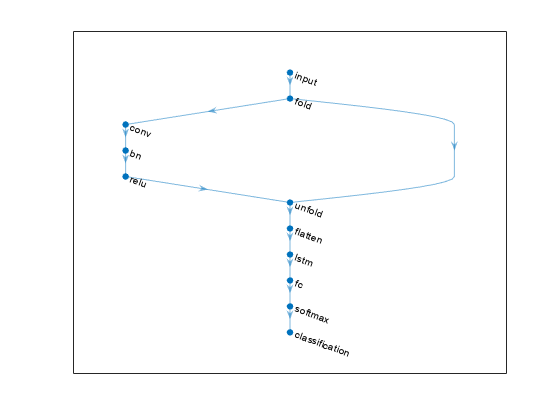
ネットワーク アーキテクチャの定義
28 x 28 のグレースケール イメージのシーケンスを 10 個のクラスに分類する分類用の LSTM ネットワークを作成します。
次のネットワーク アーキテクチャを定義します。
入力サイズ
[28 28 1]のシーケンス入力層。20 個の 5 行 5 列のフィルターを持つ、畳み込み層、バッチ正規化層、および ReLU 層のブロック。
最後のタイム ステップのみを出力する、200 個の隠れユニットを持つ LSTM 層。
サイズが 10 (クラス数) の全結合層と、その後に配置するソフトマックス層と分類層。
畳み込み演算をタイム ステップごとに個別に実行するには、畳み込み層の前にシーケンス折りたたみ層を含めます。LSTM 層はベクトル シーケンス入力を想定しています。シーケンス構造を復元し、畳み込み層の出力を特徴ベクトルのシーケンスに形状変更するには、畳み込み層と LSTM 層の間にシーケンス展開層とフラット化層を挿入します。
inputSize = [28 28 1]; filterSize = 5; numFilters = 20; numHiddenUnits = 200; numClasses = 10; layers = [ ... sequenceInputLayer(inputSize,'Name','input') sequenceFoldingLayer('Name','fold') convolution2dLayer(filterSize,numFilters,'Name','conv') batchNormalizationLayer('Name','bn') reluLayer('Name','relu') sequenceUnfoldingLayer('Name','unfold') flattenLayer('Name','flatten') lstmLayer(numHiddenUnits,'OutputMode','last','Name','lstm') fullyConnectedLayer(numClasses, 'Name','fc') softmaxLayer('Name','softmax') classificationLayer('Name','classification')];
層を層グラフに変換し、シーケンス折りたたみ層の miniBatchSize 出力をシーケンス展開層の対応する入力に結合します。
lgraph = layerGraph(layers); lgraph = connectLayers(lgraph,'fold/miniBatchSize','unfold/miniBatchSize');
関数 plot を使用して最終的なネットワーク アーキテクチャを表示します。
figure plot(lgraph)
アルゴリズム
拡張機能
バージョン履歴
R2017b で導入You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)