このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
glmfit
一般化線形回帰モデルの当てはめ
構文
説明
b = glmfit(X,y,distr,Name,Value)'Constant','off' を指定するとモデルから定数項を省略できます。
例
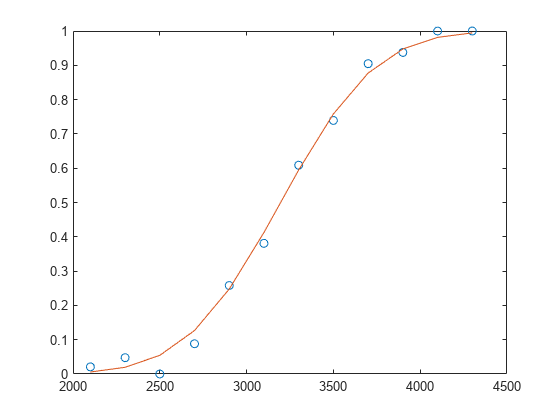
プロビット リンクによる一般化線形モデルの当てはめ
一般化線形回帰モデルを当てはめ、当てはめたモデルを使用して予測子データの予測値 (推定値) を計算します。
標本データ セットを作成します。
x = [2100 2300 2500 2700 2900 3100 ...
3300 3500 3700 3900 4100 4300]';
n = [48 42 31 34 31 21 23 23 21 16 17 21]';
y = [1 2 0 3 8 8 14 17 19 15 17 21]';x には予測子変数の値が格納されています。y の各値は対応する n の試行回数に対する成功回数です。
x における y についてのプロビット回帰モデルを当てはめます。
b = glmfit(x,[y n],'binomial','Link','probit');
推定成功回数を計算します。
yfit = glmval(b,x,'probit','Size',n);
観測された成功率と推定された成功率を x の値に対してプロットします。
plot(x,y./n,'o',x,yfit./n,'-')
カスタム リンク関数を使用した一般化線形モデルの当てはめ
カスタム リンク関数を定義し、それを使用して一般化線形回帰モデルを当てはめます。
標本データを読み込みます。
load fisheriris列ベクトル species には、3 種類のアヤメ (setosa、versicolor、virginica) が格納されています。行列 meas には、花に関する 4 種類の測定値、がく片の長さと幅 (cm) と花弁の長さと幅 (cm) が格納されています。
予測子変数と応答変数を定義します。
X = meas(51:end,:);
y = strcmp('versicolor',species(51:end));ロジット リンク関数のカスタム リンク関数を定義します。リンク関数、リンク関数の導関数、逆リンク関数を定義する 3 つの関数ハンドルを定義します。これらを cell 配列に格納します。
link = @(mu) log(mu./(1-mu));
derlink = @(mu) 1./(mu.*(1-mu));
invlink = @(resp) 1./(1+exp(-resp));
F = {link,derlink,invlink};glmfit とカスタム リンク関数を使用してロジスティック回帰モデルを当てはめます。
b = glmfit(X,y,'binomial','link',F)
b = 5×1
42.6378
2.4652
6.6809
-9.4294
-18.2861
組み込みのリンク関数 logit を使用して一般化線形モデルを当てはめ、結果を比較します。
b = glmfit(X,y,'binomial','link','logit')
b = 5×1
42.6378
2.4652
6.6809
-9.4294
-18.2861
逸脱度検定の実行
切片と各予測子の線形項を含む一般化線形回帰モデルを当てはめます。このモデルが定数モデルよりも大幅に良好な近似をしているかどうかを判別する逸脱度検定を実行します。
基となる 2 つの予測子 X(:,1) および X(:,2) のポアソン乱数を使って標本データを生成します。
rng('default') % For reproducibility rndvars = randn(100,2); X = [2 + rndvars(:,1),rndvars(:,2)]; mu = exp(1 + X*[1;2]); y = poissrnd(mu);
切片と各予測子の線形項を含む一般化線形回帰モデルを当てはめます。
[b,dev] = glmfit(X,y,'poisson');2 番目の出力引数 dev は、当てはめの逸脱度です。
切片のみを含む一般化線形回帰モデルを当てはめます。glmfit でモデルに定数項を含めないように、予測子変数を 1 の列として指定し、'Constant' を 'off' として指定します。
[~,dev_noconstant] = glmfit(ones(100,1),y,'poisson','Constant','off');
dev_constant と dev の差を計算します。
D = dev_noconstant - dev
D = 2.9533e+05
D は自由度が 2 のカイ二乗分布となります。自由度は、dev に対応するモデル内の推定パラメーターの数と定数モデル内の推定パラメーターの数の差に等しくなります。逸脱度検定の p 値を求めます。
p = 1 - chi2cdf(D,2)
p = 0
小さい p 値は、モデルが定数と大きく異なっていることを示します。
代わりに、関数fitglmを使用してポアソン データの一般化線形回帰モデルを作成することもできます。モデルの表示に統計 (Chi^2-statistic vs. constant model) と p 値が含まれます。
mdl = fitglm(X,y,'y ~ x1 + x2','Distribution','poisson')
mdl =
Generalized linear regression model:
log(y) ~ 1 + x1 + x2
Distribution = Poisson
Estimated Coefficients:
Estimate SE tStat pValue
________ _________ ______ ______
(Intercept) 1.0405 0.022122 47.034 0
x1 0.9968 0.003362 296.49 0
x2 1.987 0.0063433 313.24 0
100 observations, 97 error degrees of freedom
Dispersion: 1
Chi^2-statistic vs. constant model: 2.95e+05, p-value = 0
当てはめたモデル オブジェクトで関数devianceTestを使用することもできます。
devianceTest(mdl)
ans=2×4 table
Deviance DFE chi2Stat pValue
__________ ___ __________ ______
log(y) ~ 1 2.9544e+05 99
log(y) ~ 1 + x1 + x2 107.4 97 2.9533e+05 0
入力引数
出力引数
詳細
ヒント
glmfitは、Xまたはy内のNaNを欠損値として扱い、無視します。
代替機能
glmfit は、関数の出力引数のみが必要である場合、またはループ内でモデルの当てはめを複数回繰り返す場合に便利です。当てはめたモデルをさらに調べる必要がある場合は、fitglm または stepwiseglm を使用して一般化線形回帰モデル オブジェクト GeneralizedLinearModel を作成します。GeneralizedLinearModel オブジェクトは、glmfit より多くの機能を提供します。
当てはめたモデルを調べるには、
GeneralizedLinearModelのプロパティを使用します。オブジェクト プロパティには、係数推定値、要約統計量、当てはめ手法および入力データに関する情報が含まれています。応答の予測と、一般化線形回帰モデルの修正、評価および可視化を行うには、
GeneralizedLinearModelのオブジェクト関数を使用します。glmfitの出力に含まれる情報は、GeneralizedLinearModelのプロパティとオブジェクト関数を使用して取得できます。glmfitの出力GeneralizedLinearModelの同等の値bCoefficientsプロパティのEstimate列を参照してください。devDevianceプロパティを参照してください。statsコマンド ウィンドウのモデル表示を参照してください。統計量はモデルのプロパティ (
CoefficientCovariance、Coefficients、Dispersion、DispersionEstimated、およびResiduals) から取得できます。glmfitのstats.sDispersionプロパティの分散パラメーターは応答の分散のスケール係数です。したがって、stats.sはDispersionの値の平方根です。
参照
[1] Dobson, A. J. An Introduction to Generalized Linear Models. New York: Chapman & Hall, 1990.
[2] McCullagh, P., and J. A. Nelder. Generalized Linear Models. New York: Chapman & Hall, 1990.
[3] Collett, D. Modeling Binary Data. New York: Chapman & Hall, 2002.
拡張機能
バージョン履歴
R2006a より前に導入
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)