このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
fitrtree
回帰用のバイナリ決定木を当てはめる
構文
説明
tree = fitrtree(Tbl,ResponseVarName)Tbl 内の入力変数 (予測子、特徴量、属性とも呼ばれます) と Tbl.ResponseVarName に格納されている出力 (応答) に基づいて、回帰木を返します。返される tree は、Tbl の列の値に基づいて各枝ノードが分割される二分木です。
tree = fitrtree(___,Name,Value)
例
回帰木の構築
標本データを読み込みます。
load carsmall標本データを使用して回帰木を構築します。応答変数は、ガロンあたりの走行マイル数 (MPG) です。
tree = fitrtree([Weight, Cylinders],MPG,... 'CategoricalPredictors',2,'MinParentSize',20,... 'PredictorNames',{'W','C'})
tree =
RegressionTree
PredictorNames: {'W' 'C'}
ResponseName: 'Y'
CategoricalPredictors: 2
ResponseTransform: 'none'
NumObservations: 94
気筒数が 4、6 および 8 で、重さが約 1.8t (4,000 ポンド) の車の燃費を予測します。
MPG4Kpred = predict(tree,[4000 4; 4000 6; 4000 8])
MPG4Kpred = 3×1
19.2778
19.2778
14.3889
回帰木の深さの制御
既定では、fitrtree は深い決定木を成長させます。モデルの複雑さや計算時間の削減のために、より浅い木を成長させることもできます。木の深さを制御するには、名前と値のペアの引数 'MaxNumSplits'、'MinLeafSize' または 'MinParentSize' を使用します。
carsmall データセットを読み込みます。Displacement、Horsepower および Weight が応答 MPG の予測子であると考えます。
load carsmall
X = [Displacement Horsepower Weight];回帰木を成長させる場合、木の深さの制御に関する既定値は次のとおりです。
MaxNumSplitsはn - 1。nは学習標本のサイズです。MinLeafSizeは1。MinParentSizeは10。
これらの既定値を使用すると、学習標本のサイズが大きい場合に木が深く成長する傾向があります。
木の深さの制御について既定値を使用して、回帰木を学習させます。10 分割の交差検証をモデルに対して実行します。
rng(1); % For reproducibility MdlDefault = fitrtree(X,MPG,'CrossVal','on');
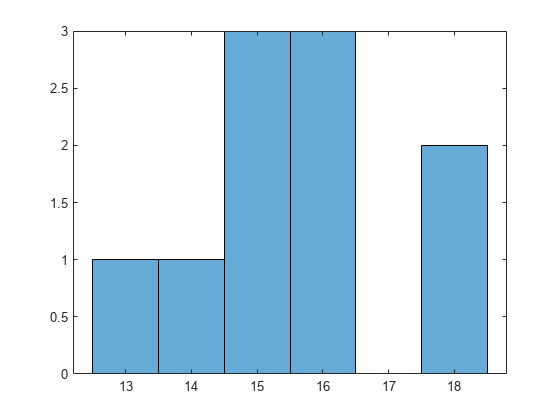
木に適用される分割数のヒストグラムを描画します。適用される分割数は、葉の数より 1 つ小さい値です。また、木の 1 つを表示します。
numBranches = @(x)sum(x.IsBranch); mdlDefaultNumSplits = cellfun(numBranches, MdlDefault.Trained); figure; histogram(mdlDefaultNumSplits)
view(MdlDefault.Trained{1},'Mode','graph')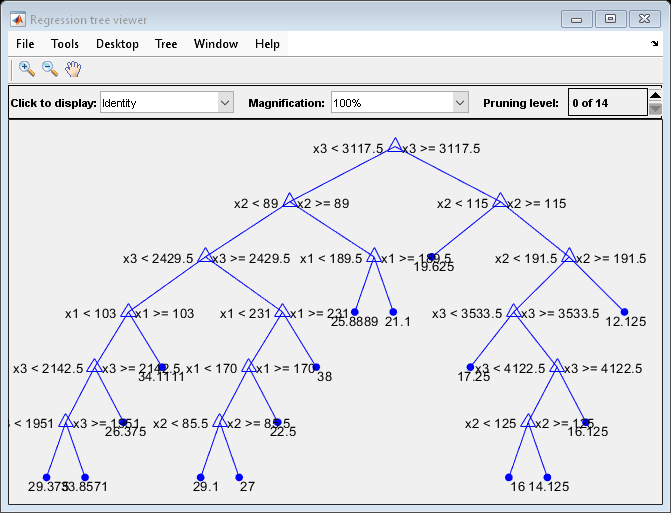
分割数の平均は 14 ~ 15 です。
既定の分割数を使用して学習させたものほど複雑ではない (深くない) 回帰木が必要であるとします。最大分割数を 7 に設定して別の回帰木を学習させます。これにより、既定値を使用した回帰木の平均分割数の約半分になります。10 分割の交差検証をモデルに対して実行します。
Mdl7 = fitrtree(X,MPG,'MaxNumSplits',7,'CrossVal','on'); view(Mdl7.Trained{1},'Mode','graph')
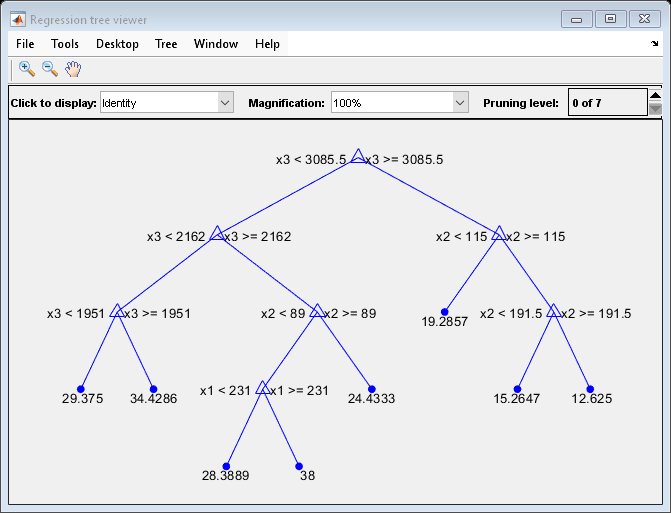
モデルの交差検証平均二乗誤差 (MSE) を比較します。
mseDefault = kfoldLoss(MdlDefault)
mseDefault = 25.7383
mse7 = kfoldLoss(Mdl7)
mse7 = 26.5748
Mdl7 は、MdlDefault より大幅に単純化されており、性能は少しだけ低下します。
回帰木の最適化
fitrtree を使用してハイパーパラメーターを自動的に最適化します。
carsmall データセットを読み込みます。
load carsmallWeight と Horsepower を MPG の予測子として使用します。自動的なハイパーパラメーター最適化を使用して、5 分割交差検証損失を最小化するハイパーパラメーターを求めます。
再現性を得るために、乱数シードを設定し、'expected-improvement-plus' の獲得関数を使用します。
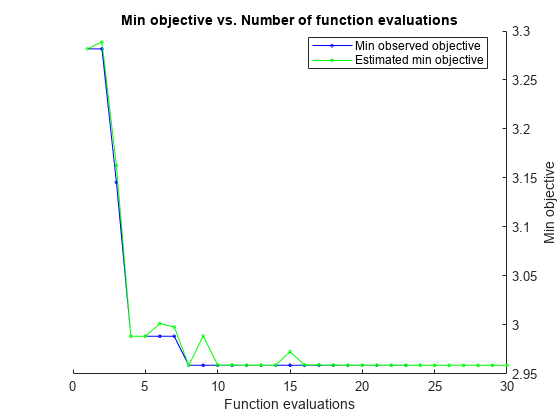
X = [Weight,Horsepower]; Y = MPG; rng default Mdl = fitrtree(X,Y,'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName',... 'expected-improvement-plus'))
|======================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | MinLeafSize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | |
|======================================================================================|
| 1 | Best | 3.2818 | 0.10065 | 3.2818 | 3.2818 | 28 |
| 2 | Accept | 3.4183 | 0.045114 | 3.2818 | 3.2888 | 1 |
| 3 | Best | 3.1457 | 0.050012 | 3.1457 | 3.1628 | 4 |
| 4 | Best | 2.9885 | 0.041731 | 2.9885 | 2.9885 | 9 |
| 5 | Accept | 2.9978 | 0.11928 | 2.9885 | 2.9885 | 7 |
| 6 | Accept | 3.0203 | 0.035057 | 2.9885 | 3.0013 | 8 |
| 7 | Accept | 2.9885 | 0.03175 | 2.9885 | 2.9981 | 9 |
| 8 | Best | 2.9589 | 0.032716 | 2.9589 | 2.9589 | 10 |
| 9 | Accept | 3.078 | 0.035296 | 2.9589 | 2.9888 | 13 |
| 10 | Accept | 4.1881 | 0.036781 | 2.9589 | 2.9592 | 50 |
| 11 | Accept | 3.4182 | 0.057886 | 2.9589 | 2.9592 | 2 |
| 12 | Accept | 3.0376 | 0.039024 | 2.9589 | 2.9591 | 6 |
| 13 | Accept | 3.1453 | 0.032691 | 2.9589 | 2.9591 | 20 |
| 14 | Accept | 2.9589 | 0.03429 | 2.9589 | 2.959 | 10 |
| 15 | Accept | 3.0123 | 0.048808 | 2.9589 | 2.9728 | 11 |
| 16 | Accept | 2.9589 | 0.038552 | 2.9589 | 2.9593 | 10 |
| 17 | Accept | 3.3055 | 0.12593 | 2.9589 | 2.9593 | 3 |
| 18 | Accept | 2.9589 | 0.148 | 2.9589 | 2.9592 | 10 |
| 19 | Accept | 3.4577 | 0.059029 | 2.9589 | 2.9591 | 37 |
| 20 | Accept | 3.2166 | 0.076674 | 2.9589 | 2.959 | 16 |
|======================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | MinLeafSize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | |
|======================================================================================|
| 21 | Accept | 3.107 | 0.058398 | 2.9589 | 2.9591 | 5 |
| 22 | Accept | 3.2818 | 0.047634 | 2.9589 | 2.959 | 24 |
| 23 | Accept | 3.3226 | 0.028967 | 2.9589 | 2.959 | 32 |
| 24 | Accept | 4.1881 | 0.040429 | 2.9589 | 2.9589 | 43 |
| 25 | Accept | 3.1789 | 0.08449 | 2.9589 | 2.9589 | 18 |
| 26 | Accept | 3.0992 | 0.043618 | 2.9589 | 2.9589 | 14 |
| 27 | Accept | 3.0556 | 0.053649 | 2.9589 | 2.9589 | 22 |
| 28 | Accept | 3.0459 | 0.034123 | 2.9589 | 2.9589 | 12 |
| 29 | Accept | 3.2818 | 0.059007 | 2.9589 | 2.9589 | 26 |
| 30 | Accept | 3.4361 | 0.052614 | 2.9589 | 2.9589 | 34 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 20.212 seconds
Total objective function evaluation time: 1.6922
Best observed feasible point:
MinLeafSize
___________
10
Observed objective function value = 2.9589
Estimated objective function value = 2.9589
Function evaluation time = 0.032716
Best estimated feasible point (according to models):
MinLeafSize
___________
10
Estimated objective function value = 2.9589
Estimated function evaluation time = 0.050761
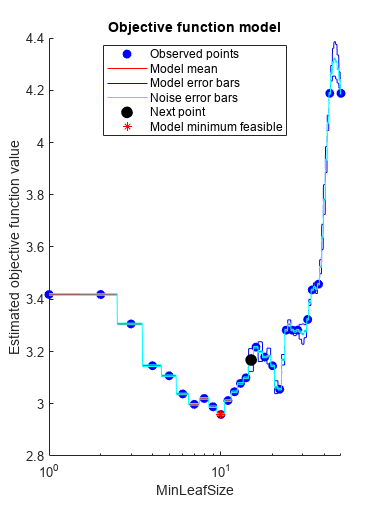
Mdl =
RegressionTree
ResponseName: 'Y'
CategoricalPredictors: []
ResponseTransform: 'none'
NumObservations: 94
HyperparameterOptimizationResults: [1x1 BayesianOptimization]
不偏予測量の重要度の推定
carsmall データセットを読み込みます。与えられた加速、気筒数、エンジン排気量、馬力、製造業者、モデル年および重量に対して自動車の燃費の平均を予測するモデルを考えます。Cylinders、Mfg および Model_Year はカテゴリカル変数であるとします。
load carsmall Cylinders = categorical(Cylinders); Mfg = categorical(cellstr(Mfg)); Model_Year = categorical(Model_Year); X = table(Acceleration,Cylinders,Displacement,Horsepower,Mfg, ... Model_Year,Weight,MPG);
カテゴリカル変数で表現されるカテゴリの個数を表示します。
numCylinders = numel(categories(Cylinders))
numCylinders = 3
numMfg = numel(categories(Mfg))
numMfg = 28
numModelYear = numel(categories(Model_Year))
numModelYear = 3
Cylinders と Model_Year には 3 つしかカテゴリがないので、予測子分割アルゴリズムの標準 CART ではこの 2 つの変数よりも連続予測子が分割されます。
データセット全体を使用して回帰木に学習をさせます。偏りの無い木を成長させるため、予測子の分割に曲率検定を使用するよう指定します。データには欠損値が含まれているので、代理分岐を使用するよう指定します。
Mdl = fitrtree(X,"MPG",PredictorSelection="curvature",Surrogate="on");
すべての予測子について分割によるリスク変動を合計し、この合計を枝ノード数で除算することにより、予測子の重要度の値を推定します。棒グラフを使用して推定を比較します。
imp = predictorImportance(Mdl); figure bar(imp) title("Predictor Importance Estimates") ylabel("Estimates") xlabel("Predictors") h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = "none";
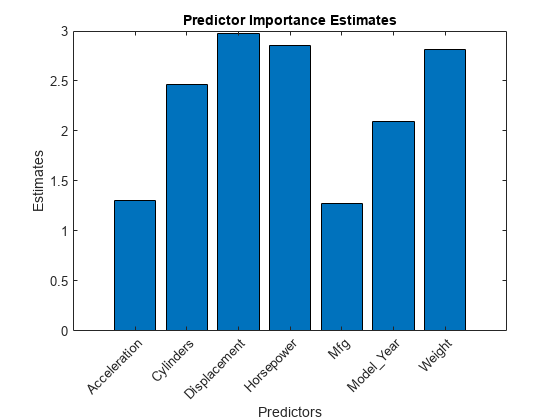
このケースでは、最も重要な予測子は Displacement であり、次に重要なのは Horsepower です。
tall 配列における最大の木の深さの制御
既定では、fitrtree は深い決定木を成長させます。tall 配列の通過回数が少なくなる、より浅い木を構築します。名前と値のペアの引数 'MaxDepth' を使用して、最大の木の深さを制御します。
tall 配列に対する計算を実行する場合、MATLAB® は並列プール (Parallel Computing Toolbox™ がある場合は既定) またはローカルの MATLAB セッションを使用します。Parallel Computing Toolbox がある場合でもローカルの MATLAB セッションを使用して例を実行するには、関数mapreducerを使用してグローバルな実行環境を変更できます。
carsmall データセットを読み込みます。Displacement、Horsepower および Weight が応答 MPG の予測子であると考えます。
load carsmall
X = [Displacement Horsepower Weight];インメモリ配列 X および MPG を tall 配列に変換します。
tx = tall(X);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
ty = tall(MPG);
すべての観測値を使用して回帰木を成長させます。可能な最大の深さまで木が成長することを許可します。
再現性を得るため、rng と tallrng を使用して乱数発生器のシードを設定します。tall 配列の場合、ワーカーの個数と実行環境によって結果が異なる可能性があります。詳細については、コードの実行場所の制御を参照してください。
rng('default') tallrng('default') Mdl = fitrtree(tx,ty);
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 2: Completed in 4.1 sec - Pass 2 of 2: Completed in 0.71 sec Evaluation completed in 6.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 1.4 sec - Pass 2 of 7: Completed in 0.29 sec - Pass 3 of 7: Completed in 1.5 sec - Pass 4 of 7: Completed in 3.3 sec - Pass 5 of 7: Completed in 0.63 sec - Pass 6 of 7: Completed in 1.2 sec - Pass 7 of 7: Completed in 2.6 sec Evaluation completed in 12 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.36 sec - Pass 2 of 7: Completed in 0.27 sec - Pass 3 of 7: Completed in 0.85 sec - Pass 4 of 7: Completed in 2 sec - Pass 5 of 7: Completed in 0.55 sec - Pass 6 of 7: Completed in 0.92 sec - Pass 7 of 7: Completed in 1.6 sec Evaluation completed in 7.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.32 sec - Pass 2 of 7: Completed in 0.29 sec - Pass 3 of 7: Completed in 0.89 sec - Pass 4 of 7: Completed in 1.9 sec - Pass 5 of 7: Completed in 0.83 sec - Pass 6 of 7: Completed in 1.2 sec - Pass 7 of 7: Completed in 2.4 sec Evaluation completed in 9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.33 sec - Pass 2 of 7: Completed in 0.28 sec - Pass 3 of 7: Completed in 0.89 sec - Pass 4 of 7: Completed in 2.4 sec - Pass 5 of 7: Completed in 0.76 sec - Pass 6 of 7: Completed in 1 sec - Pass 7 of 7: Completed in 1.7 sec Evaluation completed in 8.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.34 sec - Pass 2 of 7: Completed in 0.26 sec - Pass 3 of 7: Completed in 0.81 sec - Pass 4 of 7: Completed in 1.7 sec - Pass 5 of 7: Completed in 0.56 sec - Pass 6 of 7: Completed in 1 sec - Pass 7 of 7: Completed in 1.9 sec Evaluation completed in 7.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.35 sec - Pass 2 of 7: Completed in 0.28 sec - Pass 3 of 7: Completed in 0.81 sec - Pass 4 of 7: Completed in 1.8 sec - Pass 5 of 7: Completed in 0.76 sec - Pass 6 of 7: Completed in 0.96 sec - Pass 7 of 7: Completed in 2.2 sec Evaluation completed in 8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.35 sec - Pass 2 of 7: Completed in 0.32 sec - Pass 3 of 7: Completed in 0.92 sec - Pass 4 of 7: Completed in 1.9 sec - Pass 5 of 7: Completed in 1 sec - Pass 6 of 7: Completed in 1.5 sec - Pass 7 of 7: Completed in 2.1 sec Evaluation completed in 9.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.33 sec - Pass 2 of 7: Completed in 0.28 sec - Pass 3 of 7: Completed in 0.82 sec - Pass 4 of 7: Completed in 1.4 sec - Pass 5 of 7: Completed in 0.61 sec - Pass 6 of 7: Completed in 0.93 sec - Pass 7 of 7: Completed in 1.5 sec Evaluation completed in 6.6 sec
学習済みの木 Mdl を表示します。
view(Mdl,'Mode','graph')
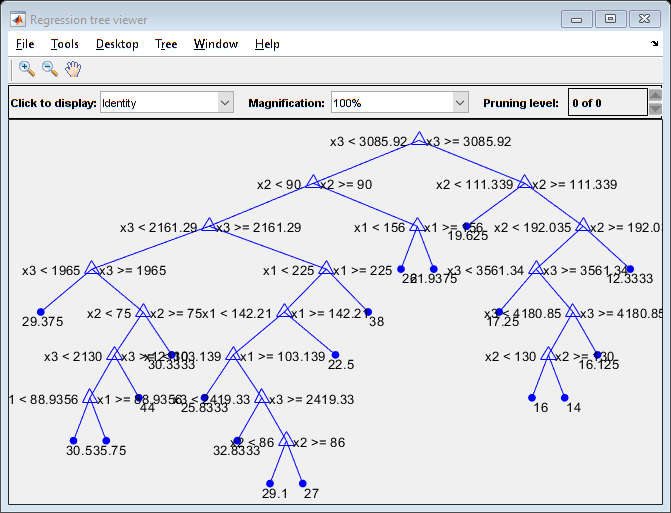
Mdl は、深さ 8 の木です。
標本内平均二乗誤差を推定します。
MSE_Mdl = gather(loss(Mdl,tx,ty))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.6 sec Evaluation completed in 1.9 sec
MSE_Mdl = 4.9078
すべての観測値を使用して回帰木を成長させます。最大の木の深さとして 4 を指定することにより、木の深さを制限します。
Mdl2 = fitrtree(tx,ty,'MaxDepth',4);Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 2: Completed in 0.27 sec - Pass 2 of 2: Completed in 0.28 sec Evaluation completed in 0.84 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.36 sec - Pass 2 of 7: Completed in 0.3 sec - Pass 3 of 7: Completed in 0.95 sec - Pass 4 of 7: Completed in 1.6 sec - Pass 5 of 7: Completed in 0.55 sec - Pass 6 of 7: Completed in 0.93 sec - Pass 7 of 7: Completed in 1.5 sec Evaluation completed in 7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.34 sec - Pass 2 of 7: Completed in 0.3 sec - Pass 3 of 7: Completed in 0.95 sec - Pass 4 of 7: Completed in 1.7 sec - Pass 5 of 7: Completed in 0.57 sec - Pass 6 of 7: Completed in 0.94 sec - Pass 7 of 7: Completed in 1.8 sec Evaluation completed in 7.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.34 sec - Pass 2 of 7: Completed in 0.3 sec - Pass 3 of 7: Completed in 0.87 sec - Pass 4 of 7: Completed in 1.5 sec - Pass 5 of 7: Completed in 0.57 sec - Pass 6 of 7: Completed in 0.81 sec - Pass 7 of 7: Completed in 1.7 sec Evaluation completed in 6.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 7: Completed in 0.32 sec - Pass 2 of 7: Completed in 0.27 sec - Pass 3 of 7: Completed in 0.85 sec - Pass 4 of 7: Completed in 1.6 sec - Pass 5 of 7: Completed in 0.63 sec - Pass 6 of 7: Completed in 0.9 sec - Pass 7 of 7: Completed in 1.6 sec Evaluation completed in 7 sec
学習済みの木 Mdl2 を表示します。
view(Mdl2,'Mode','graph')
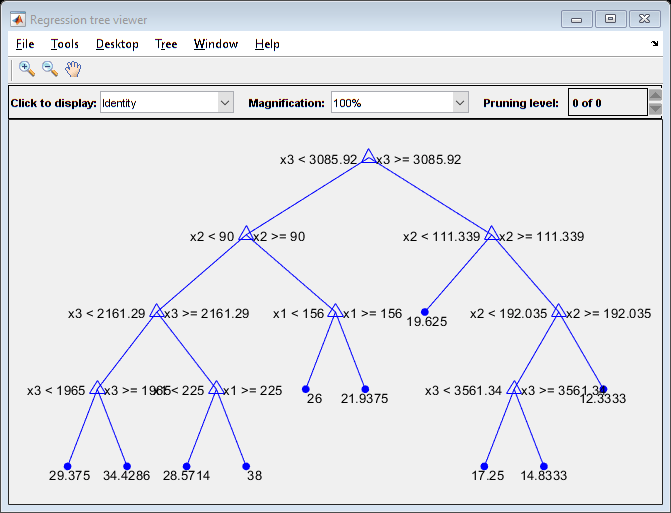
標本内平均二乗誤差を推定します。
MSE_Mdl2 = gather(loss(Mdl2,tx,ty))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.73 sec Evaluation completed in 1 sec
MSE_Mdl2 = 9.3903
Mdl2 は、複雑度が低くなった深さ 4 の木であり、標本内平均二乗誤差が Mdl の平均二乗誤差より大きくなっています。
tall 配列に対する回帰木の最適化
tall 配列を使用する回帰木のハイパーパラメーターを自動的に最適化します。標本データセットは carsmall データセットです。この例では、データセットを tall 配列に変換して、最適化手順を実行するために使用します。
tall 配列に対する計算を実行する場合、MATLAB® は並列プール (Parallel Computing Toolbox™ がある場合は既定) またはローカルの MATLAB セッションを使用します。Parallel Computing Toolbox がある場合でもローカルの MATLAB セッションを使用して例を実行するには、関数mapreducerを使用してグローバルな実行環境を変更できます。
carsmall データセットを読み込みます。Displacement、Horsepower および Weight が応答 MPG の予測子であると考えます。
load carsmall
X = [Displacement Horsepower Weight];インメモリ配列 X および MPG を tall 配列に変換します。
tx = tall(X);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
ty = tall(MPG);
名前と値のペアの引数 'OptimizeHyperparameters' を使用して、自動的にハイパーパラメーターを最適化します。ホールドアウト交差検証損失が最小になる最適な 'MinLeafSize' の値を求めます ('auto' を指定すると 'MinLeafSize' が使用されます)。再現性を得るため、'expected-improvement-plus' の獲得関数を使用し、rng と tallrng により乱数発生器のシードを設定します。tall 配列の場合、ワーカーの個数と実行環境によって結果が異なる可能性があります。詳細については、コードの実行場所の制御を参照してください。
rng('default') tallrng('default') [Mdl,FitInfo,HyperparameterOptimizationResults] = fitrtree(tx,ty,... 'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('Holdout',0.3,... 'AcquisitionFunctionName','expected-improvement-plus'))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 4.4 sec Evaluation completed in 6.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.97 sec - Pass 2 of 4: Completed in 1.6 sec - Pass 3 of 4: Completed in 3.6 sec - Pass 4 of 4: Completed in 2.4 sec Evaluation completed in 9.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 2.7 sec - Pass 4 of 4: Completed in 1.9 sec Evaluation completed in 7.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.52 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 3 sec - Pass 4 of 4: Completed in 2 sec Evaluation completed in 8.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.55 sec - Pass 2 of 4: Completed in 1.4 sec - Pass 3 of 4: Completed in 2.6 sec - Pass 4 of 4: Completed in 2 sec Evaluation completed in 7.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.61 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2.1 sec - Pass 4 of 4: Completed in 1.7 sec Evaluation completed in 6.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2.4 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 6.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.4 sec Evaluation completed in 1.7 sec |======================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | MinLeafSize | | | result | log(1+loss) | runtime | (observed) | (estim.) | | |======================================================================================| | 1 | Best | 3.2007 | 69.013 | 3.2007 | 3.2007 | 2 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.52 sec Evaluation completed in 0.83 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.65 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 3 sec - Pass 4 of 4: Completed in 2 sec Evaluation completed in 8.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.79 sec Evaluation completed in 1 sec | 2 | Error | NaN | 13.772 | NaN | 3.2007 | 46 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.52 sec Evaluation completed in 0.81 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.57 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 2.2 sec - Pass 4 of 4: Completed in 1.7 sec Evaluation completed in 6.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2.7 sec - Pass 4 of 4: Completed in 1.7 sec Evaluation completed in 6.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2.1 sec - Pass 4 of 4: Completed in 1.9 sec Evaluation completed in 6.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.72 sec Evaluation completed in 0.99 sec | 3 | Best | 3.1876 | 29.091 | 3.1876 | 3.1884 | 18 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.48 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.54 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.64 sec Evaluation completed in 0.92 sec | 4 | Best | 2.9048 | 33.465 | 2.9048 | 2.9537 | 6 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.71 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.66 sec Evaluation completed in 0.92 sec | 5 | Accept | 3.2895 | 25.902 | 2.9048 | 2.9048 | 15 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.54 sec Evaluation completed in 0.82 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2.1 sec - Pass 4 of 4: Completed in 1.9 sec Evaluation completed in 6.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 2 sec Evaluation completed in 6.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.68 sec Evaluation completed in 0.99 sec | 6 | Accept | 3.1641 | 35.522 | 2.9048 | 3.1493 | 5 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.51 sec Evaluation completed in 0.79 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.67 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 6.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.4 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.63 sec Evaluation completed in 0.89 sec | 7 | Accept | 2.9048 | 33.755 | 2.9048 | 2.9048 | 6 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.45 sec Evaluation completed in 0.75 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2.2 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 6.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.68 sec Evaluation completed in 0.97 sec | 8 | Accept | 2.9522 | 33.362 | 2.9048 | 2.9048 | 7 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.42 sec Evaluation completed in 0.71 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.49 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.64 sec Evaluation completed in 0.9 sec | 9 | Accept | 2.9985 | 32.674 | 2.9048 | 2.9048 | 8 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.43 sec Evaluation completed in 0.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.56 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 5.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.88 sec Evaluation completed in 1.2 sec | 10 | Accept | 3.0185 | 33.922 | 2.9048 | 2.9048 | 10 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.74 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 6.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.73 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 6.2 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.63 sec Evaluation completed in 0.88 sec | 11 | Accept | 3.2895 | 26.625 | 2.9048 | 2.9048 | 14 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.48 sec Evaluation completed in 0.78 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.51 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.65 sec Evaluation completed in 0.9 sec | 12 | Accept | 3.4798 | 18.111 | 2.9048 | 2.9049 | 31 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.71 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.64 sec Evaluation completed in 0.91 sec | 13 | Accept | 3.2248 | 47.436 | 2.9048 | 2.9048 | 1 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.46 sec Evaluation completed in 0.74 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.6 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.57 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2.6 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 6.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.62 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.6 sec Evaluation completed in 6.1 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.61 sec Evaluation completed in 0.88 sec | 14 | Accept | 3.1498 | 42.062 | 2.9048 | 2.9048 | 3 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.46 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.67 sec - Pass 2 of 4: Completed in 1.3 sec - Pass 3 of 4: Completed in 2.3 sec - Pass 4 of 4: Completed in 2.2 sec Evaluation completed in 7.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.6 sec Evaluation completed in 0.86 sec | 15 | Accept | 2.9048 | 34.3 | 2.9048 | 2.9048 | 6 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.48 sec Evaluation completed in 0.78 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 2 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.88 sec | 16 | Accept | 2.9048 | 32.97 | 2.9048 | 2.9048 | 6 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.43 sec Evaluation completed in 0.73 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.9 sec | 17 | Accept | 3.1847 | 17.47 | 2.9048 | 2.9048 | 23 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.43 sec Evaluation completed in 0.72 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.7 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.68 sec - Pass 2 of 4: Completed in 1.4 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 6.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.93 sec | 18 | Accept | 3.1817 | 33.346 | 2.9048 | 2.9048 | 4 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.43 sec Evaluation completed in 0.72 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.86 sec | 19 | Error | NaN | 10.235 | 2.9048 | 2.9048 | 38 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.47 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.63 sec Evaluation completed in 0.89 sec | 20 | Accept | 3.0628 | 32.459 | 2.9048 | 2.9048 | 12 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.46 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.48 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.68 sec - Pass 2 of 4: Completed in 1.7 sec - Pass 3 of 4: Completed in 2.1 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 6.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.64 sec Evaluation completed in 0.9 sec |======================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | MinLeafSize | | | result | log(1+loss) | runtime | (observed) | (estim.) | | |======================================================================================| | 21 | Accept | 3.1847 | 19.02 | 2.9048 | 2.9048 | 27 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.45 sec Evaluation completed in 0.75 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.47 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.5 sec - Pass 2 of 4: Completed in 1.6 sec - Pass 3 of 4: Completed in 2.4 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 6.8 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.5 sec Evaluation completed in 5.6 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.63 sec Evaluation completed in 0.89 sec | 22 | Accept | 3.0185 | 33.933 | 2.9048 | 2.9048 | 9 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.46 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.64 sec Evaluation completed in 0.89 sec | 23 | Accept | 3.0749 | 25.147 | 2.9048 | 2.9048 | 20 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.73 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.42 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.53 sec - Pass 2 of 4: Completed in 1.4 sec - Pass 3 of 4: Completed in 1.9 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.9 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.88 sec | 24 | Accept | 3.0628 | 32.764 | 2.9048 | 2.9048 | 11 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.73 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.2 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.61 sec Evaluation completed in 0.87 sec | 25 | Error | NaN | 10.294 | 2.9048 | 2.9048 | 34 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.73 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.87 sec | 26 | Accept | 3.1847 | 17.587 | 2.9048 | 2.9048 | 25 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.45 sec Evaluation completed in 0.73 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.3 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.66 sec Evaluation completed in 0.96 sec | 27 | Accept | 3.2895 | 24.867 | 2.9048 | 2.9048 | 16 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.74 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.4 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.6 sec Evaluation completed in 0.88 sec | 28 | Accept | 3.2135 | 24.928 | 2.9048 | 2.9048 | 13 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.47 sec Evaluation completed in 0.76 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.45 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.46 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.5 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.62 sec Evaluation completed in 0.87 sec | 29 | Accept | 3.1847 | 17.582 | 2.9048 | 2.9048 | 21 |
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.53 sec Evaluation completed in 0.81 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.44 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 4: Completed in 0.43 sec - Pass 2 of 4: Completed in 1.1 sec - Pass 3 of 4: Completed in 1.8 sec - Pass 4 of 4: Completed in 1.3 sec Evaluation completed in 5.4 sec Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 0.63 sec Evaluation completed in 0.88 sec | 30 | Accept | 3.1827 | 17.597 | 2.9048 | 2.9122 | 29 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 882.5668 seconds.
Total objective function evaluation time: 859.2122
Best observed feasible point:
MinLeafSize
___________
6
Observed objective function value = 2.9048
Estimated objective function value = 2.9122
Function evaluation time = 33.4655
Best estimated feasible point (according to models):
MinLeafSize
___________
6
Estimated objective function value = 2.9122
Estimated function evaluation time = 33.6594
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 2: Completed in 0.26 sec
- Pass 2 of 2: Completed in 0.26 sec
Evaluation completed in 0.84 sec
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 7: Completed in 0.31 sec
- Pass 2 of 7: Completed in 0.25 sec
- Pass 3 of 7: Completed in 0.75 sec
- Pass 4 of 7: Completed in 1.2 sec
- Pass 5 of 7: Completed in 0.45 sec
- Pass 6 of 7: Completed in 0.69 sec
- Pass 7 of 7: Completed in 1.2 sec
Evaluation completed in 5.7 sec
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 7: Completed in 0.28 sec
- Pass 2 of 7: Completed in 0.24 sec
- Pass 3 of 7: Completed in 0.75 sec
- Pass 4 of 7: Completed in 1.2 sec
- Pass 5 of 7: Completed in 0.46 sec
- Pass 6 of 7: Completed in 0.67 sec
- Pass 7 of 7: Completed in 1.2 sec
Evaluation completed in 5.6 sec
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 7: Completed in 0.32 sec
- Pass 2 of 7: Completed in 0.25 sec
- Pass 3 of 7: Completed in 0.71 sec
- Pass 4 of 7: Completed in 1.2 sec
- Pass 5 of 7: Completed in 0.47 sec
- Pass 6 of 7: Completed in 0.66 sec
- Pass 7 of 7: Completed in 1.2 sec
Evaluation completed in 5.6 sec
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 7: Completed in 0.29 sec
- Pass 2 of 7: Completed in 0.25 sec
- Pass 3 of 7: Completed in 0.73 sec
- Pass 4 of 7: Completed in 1.2 sec
- Pass 5 of 7: Completed in 0.46 sec
- Pass 6 of 7: Completed in 0.68 sec
- Pass 7 of 7: Completed in 1.2 sec
Evaluation completed in 5.5 sec
Evaluating tall expression using the Parallel Pool 'local':
- Pass 1 of 7: Completed in 0.27 sec
- Pass 2 of 7: Completed in 0.25 sec
- Pass 3 of 7: Completed in 0.75 sec
- Pass 4 of 7: Completed in 1.2 sec
- Pass 5 of 7: Completed in 0.47 sec
- Pass 6 of 7: Completed in 0.69 sec
- Pass 7 of 7: Completed in 1.2 sec
Evaluation completed in 5.6 sec
Mdl =
CompactRegressionTree
ResponseName: 'Y'
CategoricalPredictors: []
ResponseTransform: 'none'
Properties, Methods
FitInfo = struct with no fields.
HyperparameterOptimizationResults =
BayesianOptimization with properties:
ObjectiveFcn: @createObjFcn/tallObjFcn
VariableDescriptions: [3×1 optimizableVariable]
Options: [1×1 struct]
MinObjective: 2.9048
XAtMinObjective: [1×1 table]
MinEstimatedObjective: 2.9122
XAtMinEstimatedObjective: [1×1 table]
NumObjectiveEvaluations: 30
TotalElapsedTime: 882.5668
NextPoint: [1×1 table]
XTrace: [30×1 table]
ObjectiveTrace: [30×1 double]
ConstraintsTrace: []
UserDataTrace: {30×1 cell}
ObjectiveEvaluationTimeTrace: [30×1 double]
IterationTimeTrace: [30×1 double]
ErrorTrace: [30×1 double]
FeasibilityTrace: [30×1 logical]
FeasibilityProbabilityTrace: [30×1 double]
IndexOfMinimumTrace: [30×1 double]
ObjectiveMinimumTrace: [30×1 double]
EstimatedObjectiveMinimumTrace: [30×1 double]
入力引数
出力引数
詳細
ヒント
アルゴリズム
参照
[1] Breiman, L., J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Boca Raton, FL: CRC Press, 1984.
[2] Loh, W.Y. “Regression Trees with Unbiased Variable Selection and Interaction Detection.” Statistica Sinica, Vol. 12, 2002, pp. 361–386.
[3] Loh, W.Y. and Y.S. Shih. “Split Selection Methods for Classification Trees.” Statistica Sinica, Vol. 7, 1997, pp. 815–840.
拡張機能
バージョン履歴
R2014a で導入
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)