このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
fitcsvm
1 クラスおよびバイナリ分類用のサポート ベクター マシン (SVM) 分類器の学習
構文
説明
fitcsvm は、低~中次元の予測子データセットにおける 1 クラスおよび 2 クラス (バイナリ) 分類について、サポート ベクター マシン (SVM) モデルに学習をさせるか、その交差検証を行います。fitcsvm は、カーネル関数を使用する予測子データのマッピングをサポートし、逐次最小最適化 (SMO)、反復単一データ アルゴリズム (ISDA)、または二次計画法による L1 ソフト マージン最小化を目的関数最小化についてサポートします。
高次元データセット、つまり多数の予測子変数が含まれているデータセットに対するバイナリ分類の場合に線形 SVM モデルに学習をさせるには、代わりに fitclinear を使用します。
バイナリ SVM モデルが結合されたマルチクラス学習の場合は、誤り訂正出力符号 (ECOC) を使用します。詳細は、fitcecocを参照してください。
SVM 回帰モデルに学習をさせる方法については、低~中次元の予測子データセットの場合は fitrsvm、高次元データセットの場合は fitrlinear を参照してください。
Mdl = fitcsvm(Tbl,ResponseVarName)Tbl に格納されている標本データを使用して学習させたサポート ベクター マシン (SVM) 分類器 Mdl を返します。ResponseVarName は、1 クラスまたは 2 クラス分類用のクラス ラベルが含まれている Tbl 内の変数の名前です。
クラス ラベル変数に 1 つしかクラスが含まれていない (たとえば、1 クラスのベクトル) 場合、fitcsvm は 1 クラス分類用にモデルを学習させます。そうでない場合、関数は 2 クラス分類用にモデルを学習させます。
Mdl = fitcsvm(___,Name,Value)
例
SVM 分類器の学習
フィッシャーのアヤメのデータセットを読み込みます。がく片の長さと幅および観測済みのすべての setosa 種のアヤメを削除します。
load fisheriris inds = ~strcmp(species,'setosa'); X = meas(inds,3:4); y = species(inds);
処理済みのデータセットを使用して SVM 分類器に学習させます。
SVMModel = fitcsvm(X,y)
SVMModel =
ClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 100
Alpha: [24x1 double]
Bias: -14.4149
KernelParameters: [1x1 struct]
BoxConstraints: [100x1 double]
ConvergenceInfo: [1x1 struct]
IsSupportVector: [100x1 logical]
Solver: 'SMO'
SVMModel は学習させた ClassificationSVM 分類器です。SVMModel のプロパティを表示します。たとえば、クラスの順序を確認するには、ドット表記を使用します。
classOrder = SVMModel.ClassNames
classOrder = 2x1 cell
{'versicolor'}
{'virginica' }
最初のクラス ('versicolor') は陰性のクラスで、2 番目のクラス ('virginica') は陽性のクラスです。'ClassNames' 名前と値のペアの引数を使用すると、学習中にクラスの順序を変更できます。
データの散布図をプロットし、サポート ベクターを円で囲みます。
sv = SVMModel.SupportVectors; figure gscatter(X(:,1),X(:,2),y) hold on plot(sv(:,1),sv(:,2),'ko','MarkerSize',10) legend('versicolor','virginica','Support Vector') hold off
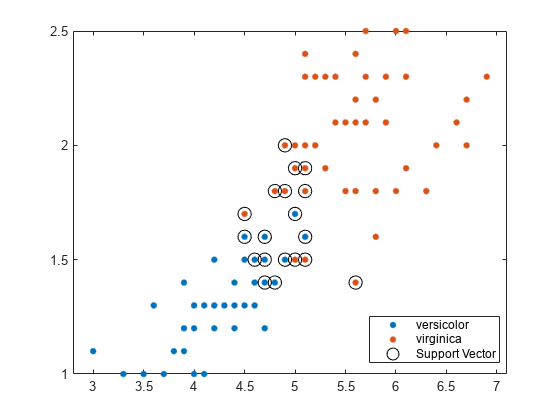
サポート ベクターは、推定されたクラス境界の上または外側で発生する観測値です。
名前と値のペアの引数 'BoxConstraint' を使用して学習時のボックス制約を設定すると、境界 (および結果的にサポート ベクターの個数) を調整できます。
2 クラス SVM 分類器の判定境界とマージンのラインのプロット
この例では、2 つの予測子変数をもつ 2 クラス (バイナリ) SVM 分類器の判定境界とマージンのラインをプロットする方法を示します。
フィッシャーのアヤメのデータセットを読み込みます。versicolor 種のアヤメはすべて除外し (setosa 種と virginica 種だけを残し)、がく片の長さと幅の測定値のみを残します。
load fisheriris; inds = ~strcmp(species,'versicolor'); X = meas(inds,1:2); s = species(inds);
線形カーネル SVM 分類器に学習させます。
SVMModel = fitcsvm(X,s);
SVMModel は学習させた ClassificationSVM 分類器です。プロパティには、サポート ベクター、線形予測子の係数、およびバイアス項が含まれます。
sv = SVMModel.SupportVectors; % Support vectors beta = SVMModel.Beta; % Linear predictor coefficients b = SVMModel.Bias; % Bias term
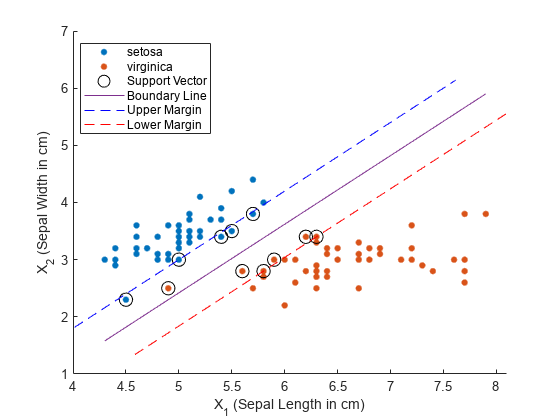
データの散布図をプロットし、サポート ベクターを円で囲みます。サポート ベクターは、推定されたクラス境界の上または外側で発生する観測値です。
hold on gscatter(X(:,1),X(:,2),s) plot(sv(:,1),sv(:,2),'ko','MarkerSize',10)
SVMModel 分類器の最適な分離超平面は、 で指定される直線です。2 つの種類の間の判定境界を実線でプロットします。
X1 = linspace(min(X(:,1)),max(X(:,1)),100);
X2 = -(beta(1)/beta(2)*X1)-b/beta(2);
plot(X1,X2,'-')線形予測子の係数 で判定境界と直交するベクトルが定義されます。マージンの最大幅は です (詳細については、バイナリ分類のサポート ベクター マシンを参照してください)。マージンの最大境界を破線でプロットします。軸のラベルを設定し、凡例を追加します。
m = 1/sqrt(beta(1)^2 + beta(2)^2); % Margin half-width X1margin_low = X1+beta(1)*m^2; X2margin_low = X2+beta(2)*m^2; X1margin_high = X1-beta(1)*m^2; X2margin_high = X2-beta(2)*m^2; plot(X1margin_high,X2margin_high,'b--') plot(X1margin_low,X2margin_low,'r--') xlabel('X_1 (Sepal Length in cm)') ylabel('X_2 (Sepal Width in cm)') legend('setosa','virginica','Support Vector', ... 'Boundary Line','Upper Margin','Lower Margin') hold off
SVM 分類器の学習と交差検証
ionosphere データセットを読み込みます。
load ionosphere rng(1); % For reproducibility
放射基底関数を使用して SVM 分類器に学習させます。本ソフトウェアを使用してカーネル関数のスケール値を検出します。予測子を標準化します。
SVMModel = fitcsvm(X,Y,'Standardize',true,'KernelFunction','RBF',... 'KernelScale','auto');
SVMModel は学習させた ClassificationSVM 分類器です。
SVM 分類器を交差検証します。既定では、10 分割交差検証が使用されます。
CVSVMModel = crossval(SVMModel);
CVSVMModel は ClassificationPartitionedModel 交差検証分類器です。
標本外誤分類率を推定します。
classLoss = kfoldLoss(CVSVMModel)
classLoss = 0.0484
汎化率は約 5% です。
SVM および 1 クラス学習を使用した外れ値の検出
すべてのアヤメを同じクラスに割り当てることにより、フィッシャーのアヤメのデータセットを変更します。修正したデータセットの外れ値を検出し、外れ値である観測値の比率が予想どおりであることを確認します。
フィッシャーのアヤメのデータセットを読み込みます。花弁の長さと幅を削除します。すべてのアヤメを同じクラスとして扱います。
load fisheriris
X = meas(:,1:2);
y = ones(size(X,1),1);修正したデータセットを使用して SVM 分類器に学習させます。観測値のうち 5% が外れ値であるとします。予測子を標準化します。
rng(1); SVMModel = fitcsvm(X,y,'KernelScale','auto','Standardize',true,... 'OutlierFraction',0.05);
SVMModel は学習させた ClassificationSVM 分類器です。既定では、1 クラス学習にはガウス カーネルが使用されます。
観測値と判定境界をプロットします。サポート ベクターと外れ値の可能性がある値にフラグを設定します。
svInd = SVMModel.IsSupportVector; h = 0.02; % Mesh grid step size [X1,X2] = meshgrid(min(X(:,1)):h:max(X(:,1)),... min(X(:,2)):h:max(X(:,2))); [~,score] = predict(SVMModel,[X1(:),X2(:)]); scoreGrid = reshape(score,size(X1,1),size(X2,2)); figure plot(X(:,1),X(:,2),'k.') hold on plot(X(svInd,1),X(svInd,2),'ro','MarkerSize',10) contour(X1,X2,scoreGrid) colorbar; title('{\bf Iris Outlier Detection via One-Class SVM}') xlabel('Sepal Length (cm)') ylabel('Sepal Width (cm)') legend('Observation','Support Vector') hold off
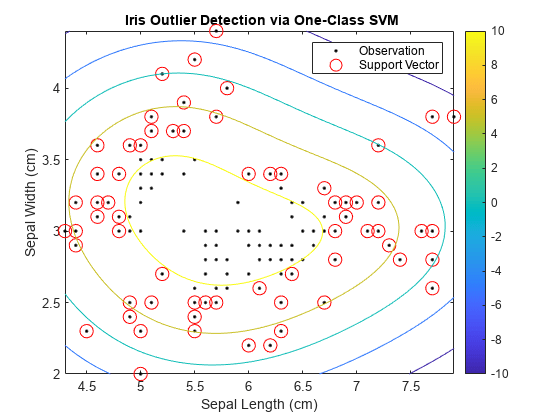
外れ値と他のデータとの境界は、等高線値が 0 である場所で発生します。
交差検証データで負のスコアをもつ観測値のごく一部が、約 5% であることを確認します。
CVSVMModel = crossval(SVMModel); [~,scorePred] = kfoldPredict(CVSVMModel); outlierRate = mean(scorePred<0)
outlierRate = 0.0467
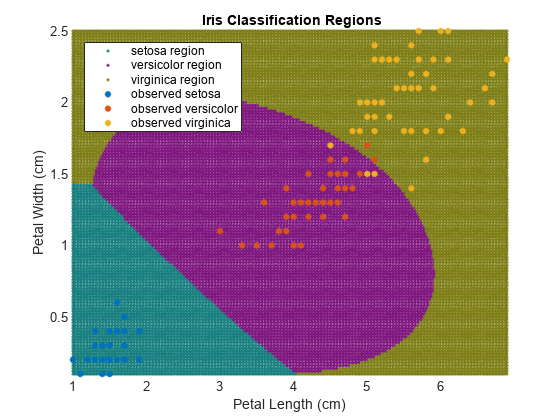
バイナリ SVM を使用した複数クラス境界の検出
fisheriris データセットの散布図を作成します。プロット内のグリッドの座標をデータセットの分布から派生する新しい観測値として扱い、データセット内の 3 つのクラスのいずれかに座標を割り当てることによりクラスの境界を求めます。
フィッシャーのアヤメのデータセットを読み込みます。花弁の長さと幅を予測子として使用します。
load fisheriris
X = meas(:,3:4);
Y = species;データの散布図を調べます。
figure gscatter(X(:,1),X(:,2),Y); h = gca; lims = [h.XLim h.YLim]; % Extract the x and y axis limits title('{\bf Scatter Diagram of Iris Measurements}'); xlabel('Petal Length (cm)'); ylabel('Petal Width (cm)'); legend('Location','Northwest');
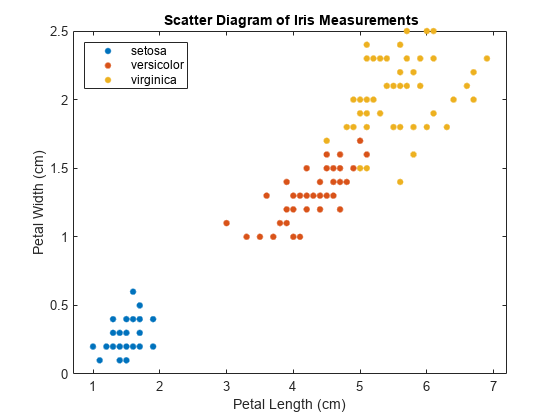
データには 3 つのクラスが含まれており、そのうち 1 つは他のクラスから線形分離可能です。
各クラスに対して、以下を実行します。
観測値がクラスのメンバーであるかどうかを示す logical ベクトル (
indx) を作成します。予測子データと
indxを使用して SVM 分類器に学習させます。分類器を cell 配列のセルに保存します。
クラスの順序を定義します。
SVMModels = cell(3,1); classes = unique(Y); rng(1); % For reproducibility for j = 1:numel(classes) indx = strcmp(Y,classes(j)); % Create binary classes for each classifier SVMModels{j} = fitcsvm(X,indx,'ClassNames',[false true],'Standardize',true,... 'KernelFunction','rbf','BoxConstraint',1); end
SVMModels は 3 行 1 列の cell 配列です。ここで、各セルには ClassificationSVM 分類器が格納されています。各セルで、陽性のクラスはそれぞれ setosa、versicolor、virginica です。
プロット内で細かいグリッドを定義し、座標を学習データの分布からの新しい観測値として扱います。各分類器を使用して、この新しい測定値のスコアを推定します。
d = 0.02; [x1Grid,x2Grid] = meshgrid(min(X(:,1)):d:max(X(:,1)),... min(X(:,2)):d:max(X(:,2))); xGrid = [x1Grid(:),x2Grid(:)]; N = size(xGrid,1); Scores = zeros(N,numel(classes)); for j = 1:numel(classes) [~,score] = predict(SVMModels{j},xGrid); Scores(:,j) = score(:,2); % Second column contains positive-class scores end
Scores の各行には 3 つのスコアが格納されています。スコアが最大の要素のインデックスは、新しいクラスの観測値の所属先となる可能性が最も高いと思われるクラスのインデックスです。
新しいそれぞれの観測値を、当該の観測値に最大スコアを設定する分類器に関連付けます。
[~,maxScore] = max(Scores,[],2);
プロットの各領域の色は、対応する新しい観測値が属するクラスに基づいています。
figure h(1:3) = gscatter(xGrid(:,1),xGrid(:,2),maxScore,... [0.1 0.5 0.5; 0.5 0.1 0.5; 0.5 0.5 0.1]); hold on h(4:6) = gscatter(X(:,1),X(:,2),Y); title('{\bf Iris Classification Regions}'); xlabel('Petal Length (cm)'); ylabel('Petal Width (cm)'); legend(h,{'setosa region','versicolor region','virginica region',... 'observed setosa','observed versicolor','observed virginica'},... 'Location','Northwest'); axis tight hold off
SVM 分類器の最適化
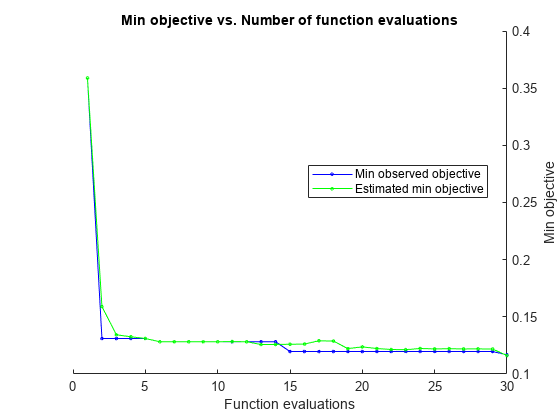
fitcsvm を使用してハイパーパラメーターを自動的に最適化します。
ionosphere データセットを読み込みます。
load ionosphere自動的なハイパーパラメーター最適化を使用して、5 分割交差検証損失を最小化するハイパーパラメーターを求めます。再現性を得るために、乱数シードを設定し、'expected-improvement-plus' の獲得関数を使用します。
rng default Mdl = fitcsvm(X,Y,'OptimizeHyperparameters','auto', ... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName', ... 'expected-improvement-plus'))
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | BoxConstraint| KernelScale | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 1 | Best | 0.35897 | 2.1505 | 0.35897 | 0.35897 | 3.8653 | 961.53 | true |
| 2 | Best | 0.1339 | 13.892 | 0.1339 | 0.16146 | 429.99 | 0.2378 | false |
| 3 | Accept | 0.35897 | 0.21678 | 0.1339 | 0.13712 | 0.11801 | 8.9479 | false |
| 4 | Accept | 0.1339 | 8.0874 | 0.1339 | 0.13515 | 0.0010694 | 0.0032063 | true |
| 5 | Best | 0.13105 | 1.5358 | 0.13105 | 0.13108 | 568.72 | 2.2544 | false |
| 6 | Best | 0.12821 | 14.187 | 0.12821 | 0.12823 | 0.0067651 | 0.0016188 | true |
| 7 | Best | 0.11966 | 0.21665 | 0.11966 | 0.11979 | 0.0030634 | 0.041782 | true |
| 8 | Accept | 0.1339 | 13.329 | 0.11966 | 0.11971 | 997.63 | 0.80596 | true |
| 9 | Accept | 0.35897 | 0.11484 | 0.11966 | 0.11968 | 0.001005 | 5.8605 | false |
| 10 | Accept | 0.23932 | 15.981 | 0.11966 | 0.11976 | 84.975 | 0.00562 | true |
| 11 | Accept | 0.20513 | 16.163 | 0.11966 | 0.11978 | 24.412 | 0.001408 | false |
| 12 | Accept | 0.35897 | 0.12929 | 0.11966 | 0.11968 | 0.0031461 | 6.6654 | true |
| 13 | Accept | 0.1339 | 4.1122 | 0.11966 | 0.1197 | 0.022631 | 0.012497 | true |
| 14 | Accept | 0.1396 | 0.10146 | 0.11966 | 0.11971 | 991.42 | 136.85 | false |
| 15 | Accept | 0.1339 | 0.82435 | 0.11966 | 0.11972 | 0.0030154 | 0.012778 | true |
| 16 | Accept | 0.12821 | 1.2305 | 0.11966 | 0.11972 | 0.49783 | 0.12412 | true |
| 17 | Accept | 0.35897 | 0.18339 | 0.11966 | 0.11967 | 932.16 | 968.59 | false |
| 18 | Accept | 0.1339 | 0.14851 | 0.11966 | 0.11967 | 982.66 | 33.78 | false |
| 19 | Accept | 0.20798 | 15.893 | 0.11966 | 0.11967 | 882.21 | 0.19197 | true |
| 20 | Accept | 0.13675 | 10.109 | 0.11966 | 0.11967 | 963.39 | 0.7896 | false |
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | BoxConstraint| KernelScale | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 21 | Accept | 0.21652 | 15.781 | 0.11966 | 0.11967 | 965.01 | 0.028437 | false |
| 22 | Accept | 0.1339 | 4.2327 | 0.11966 | 0.11967 | 952.24 | 3.3726 | true |
| 23 | Accept | 0.12536 | 0.49759 | 0.11966 | 0.1197 | 0.03224 | 0.067737 | true |
| 24 | Accept | 0.13105 | 1.2061 | 0.11966 | 0.1197 | 23.948 | 0.95371 | true |
| 25 | Best | 0.11681 | 0.10776 | 0.11681 | 0.11682 | 0.0012463 | 0.12747 | true |
| 26 | Accept | 0.13105 | 0.23966 | 0.11681 | 0.11682 | 0.038136 | 0.059607 | false |
| 27 | Accept | 0.1396 | 0.24915 | 0.11681 | 0.11682 | 0.0010048 | 0.0068725 | false |
| 28 | Accept | 0.1339 | 0.8721 | 0.11681 | 0.11682 | 3.5757 | 0.20235 | false |
| 29 | Accept | 0.1339 | 12.441 | 0.11681 | 0.11682 | 0.0011575 | 0.0010168 | false |
| 30 | Accept | 0.11966 | 0.2175 | 0.11681 | 0.11682 | 0.074799 | 0.26374 | true |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 180.4089 seconds
Total objective function evaluation time: 154.45
Best observed feasible point:
BoxConstraint KernelScale Standardize
_____________ ___________ ___________
0.0012463 0.12747 true
Observed objective function value = 0.11681
Estimated objective function value = 0.11682
Function evaluation time = 0.10776
Best estimated feasible point (according to models):
BoxConstraint KernelScale Standardize
_____________ ___________ ___________
0.0012463 0.12747 true
Estimated objective function value = 0.11682
Estimated function evaluation time = 0.098264
Mdl =
ClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 351
HyperparameterOptimizationResults: [1x1 BayesianOptimization]
Alpha: [115x1 double]
Bias: 0.2530
KernelParameters: [1x1 struct]
Mu: [0.8917 0 0.6413 0.0444 0.6011 0.1159 0.5501 0.1194 0.5118 0.1813 0.4762 0.1550 0.4008 0.0934 0.3442 0.0711 0.3819 -0.0036 0.3594 -0.0240 0.3367 0.0083 0.3625 -0.0574 0.3961 -0.0712 0.5416 -0.0695 ... ] (1x34 double)
Sigma: [0.3112 0 0.4977 0.4414 0.5199 0.4608 0.4927 0.5207 0.5071 0.4839 0.5635 0.4948 0.6222 0.4949 0.6528 0.4584 0.6180 0.4968 0.6263 0.5191 0.6098 0.5182 0.6038 0.5275 0.5785 0.5085 0.5162 0.5500 ... ] (1x34 double)
BoxConstraints: [351x1 double]
ConvergenceInfo: [1x1 struct]
IsSupportVector: [351x1 logical]
Solver: 'SMO'
入力引数
出力引数
制限
fitcsvmは、1 クラスまたは 2 クラスの学習アプリケーションの場合に SVM 分類器に学習をさせます。クラスが 3 つ以上あるデータを使用して SVM 分類器を学習させるには、fitcecocを使用します。fitcsvmは、低~中次元のデータセットをサポートします。高次元データセットの場合は、代わりにfitclinearを使用してください。
詳細
ヒント
データセットが大規模でない限り、常に予測子を標準化してください (
Standardizeを参照してください)。標準化を行うと、予測子を測定するスケールの影響を受けなくなります。名前と値のペアの引数
KFoldを使用して交差検証を行うことをお勧めします。この交差検証の結果により、SVM 分類器の一般化の精度がわかります。1 クラス学習では、以下のようになります。
サポート ベクターのスパース性は SVM 分類器の望ましい特性です。サポート ベクターの数を少なくするには、
BoxConstraintを大きい値に設定します。この場合、学習時間が長くなります。学習時間を最適にするには、使用しているコンピューターで許容されるメモリの制限値まで
CacheSizeを大きくします。サポート ベクターの個数が学習セット内の観測値数よりはるかに少ないと考えられる場合、名前と値のペアの引数
'ShrinkagePeriod'を使用してアクティブ セットを縮小すると、収束を大幅に高速化することができます。'ShrinkagePeriod',1000を指定することをお勧めします。判定境界から離れている重複する観測値は、収束に影響を与えません。しかし、重複する観測値が判定境界の近くに少しでもあると、収束が大幅に遅くなる可能性があります。収束を高速化するには、次の場合に
'RemoveDuplicates',trueを指定します。多数の重複する観測値がデータセットに含まれている。
少数の重複する観測値が判定境界の近くにあると考えられる。
学習時に元のデータセットを維持するため、
fitcsvmは別々のデータセット、つまり元のデータセットおよび重複する観測値を除外したデータセットを一時的に格納しなければなりません。このため、重複がほとんど含まれていないデータセットの場合にtrueを指定すると、fitcsvmは元のデータの場合の 2 倍に近いメモリを消費します。モデルに学習をさせた後で、新しいデータについてラベルを予測する C/C++ コードを生成できます。C/C++ コードの生成には MATLAB Coder™ が必要です。詳細については、コード生成の紹介を参照してください。
アルゴリズム
SVM バイナリ分類アルゴリズムの数学的定式化については、バイナリ分類のサポート ベクター マシンとサポート ベクター マシンについてを参照してください。
NaN、<undefined>、空の文字ベクトル ('')、空の string ("")、および<missing>値は、欠損値を示します。fitcsvmは、欠損応答に対応するデータ行全体を削除します。fitcsvmは、重みの合計を計算するときに (以下の項目を参照)、欠損している予測子が 1 つ以上ある観測値に対応する重みを無視します。これにより、平衡なクラスの問題で不平衡な事前確率が発生する可能性があります。したがって、観測値のボックス制約がBoxConstraintに等しくならない可能性があります。名前と値の引数
Cost、Prior、およびWeightsを指定すると、出力モデル オブジェクトにCost、Prior、およびWの各プロパティの指定値がそれぞれ格納されます。Costプロパティには、ユーザー指定のコスト行列 (C) が変更なしで格納されます。PriorプロパティとWプロパティには、正規化後の事前確率と観測値の重みがそれぞれ格納されます。モデルの学習用に、事前確率と観測値の重みが更新されて、コスト行列で指定されているペナルティが組み込まれます。詳細については、誤分類コスト行列、事前確率、および観測値の重みを参照してください。名前と値の引数
CostおよびPriorは 2 クラス学習用であることに注意してください。1 クラス学習の場合、Costプロパティには0、Priorプロパティには1が格納されます。2 クラス学習の場合、
fitcsvmは学習データの各観測値にボックス制約を割り当てます。観測値 j のボックス制約の式は、次のようになります。ここで、C0 は初期のボックス制約 (名前と値の引数
BoxConstraintを参照)、wj* は観測値 j のCostとPriorで調整された観測値の重みです。観測値の重みの詳細については、誤分類コスト行列に応じた事前確率と観測値の重みの調整を参照してください。Standardizeをtrueとして指定し、名前と値の引数Cost、Prior、またはWeightsを設定した場合、fitcsvmは対応する加重平均および加重標準偏差を使用して予測子を標準化します。つまり、fitcsvmは、以下を使用して予測子 j (xj) を標準化します。ここで、xjk は予測子 j (列) の観測値 k (行) であり、次のようになります。
pは学習データで予期される外れ値の比率であり、'OutlierFraction',pを設定したと仮定します。1 クラス学習では、バイアス項の学習により、学習データの観測値のうち 100
p% が負のスコアをもつようになります。2 クラス学習では "ロバスト学習" が行われます。この方式では、最適化アルゴリズムが収束すると、観測値のうち 100
p% の削除が試行されます。削除された観測値は、勾配の大きいものに対応します。
予測子データにカテゴリカル変数が含まれている場合、一般にこれらの変数について完全なダミー エンコードが使用されます。各カテゴリカル変数の各レベルについて、1 つずつダミー変数が作成されます。
PredictorNamesプロパティには、元の予測子変数名のそれぞれについて 1 つずつ要素が格納されます。たとえば、3 つの予測子があり、そのうちの 1 つは 3 つのレベルがあるカテゴリカル変数であるとします。この場合、PredictorNamesは元の予測子変数名が含まれている 1 行 3 列の文字ベクトルの cell 配列になります。ExpandedPredictorNamesプロパティには、ダミー変数を含む予測子変数のそれぞれについて 1 つずつ要素が格納されます。たとえば、3 つの予測子があり、そのうちの 1 つは 3 つのレベルがあるカテゴリカル変数であるとします。この場合、ExpandedPredictorNamesは予測子変数および新しいダミー変数の名前が含まれている 1 行 5 列の文字ベクトルの cell 配列になります。同様に、
Betaプロパティには、ダミー変数を含む各予測子について 1 つずつベータ係数が格納されます。SupportVectorsプロパティには、ダミー変数を含むサポート ベクターの予測子の値が格納されます。たとえば、m 個のサポート ベクターと 3 つの予測子があり、そのうちの 1 つは 3 つのレベルがあるカテゴリカル変数であるとします。この場合、SupportVectorsは n 行 5 列の行列になります。Xプロパティには、はじめに入力されたときの状態で学習データが格納され、ダミー変数は含まれません。入力がテーブルの場合、Xには予測子として使用した列のみが格納されます。
テーブルで予測子を指定した場合、いずれかの変数に順序付きのカテゴリが含まれていると、これらの変数について順序付きエンコードが使用されます。
k 個の順序付きレベルが変数に含まれている場合、k – 1 個のダミー変数が作成されます。j 番目のダミー変数は、j までのレベルについては –1、j + 1 から k までのレベルについては +1 になります。
ExpandedPredictorNamesプロパティに格納されるダミー変数の名前は 1 番目のレベルを示し、値は +1 になります。レベル 2, 3, ..., k の名前を含む k – 1 個の追加予測子名がダミー変数について格納されます。
どのソルバーも L1 ソフト マージン最小化を実装します。
1 クラス学習の場合、次の条件を満たすラグランジュ乗数 α1,...,αn が推定されます。
代替機能
異常検出用の 1 クラス SVM モデルの学習には、関数 ocsvm も使用できます。
関数
ocsvmは、関数fitcsvmよりも簡単で推奨される異常検出用のワークフローを提供します。関数
ocsvmは、OneClassSVMオブジェクト、異常インジケーター、および異常スコアを返します。その出力を使用して学習データの異常を特定できます。新規のデータの異常を見つけるには、OneClassSVMのオブジェクト関数isanomalyを使用できます。関数isanomalyは、新規データの異常インジケーターおよびスコアを返します。関数
fitcsvmは、1 クラスとバイナリの両方の分類をサポートします。クラス ラベル変数に 1 つしかクラスが含まれていない場合 (1 のベクトルの場合など)、fitcsvmは 1 クラス分類用にモデルを学習させ、ClassificationSVMオブジェクトを返します。異常を特定するには、最初にClassificationSVMのオブジェクト関数resubPredictまたはpredictを使用して異常スコアを計算してから、負のスコアをもつ観測値を探して異常を特定する必要があります。ocsvmでは大きい正の異常スコアが異常を示すのに対し、ClassificationSVMのpredictでは負のスコアが異常を示すことに注意してください。
関数
ocsvmは SVM の主問題形式に基づいて判定境界を求めるのに対し、関数fitcsvmは SVM の双対問題形式に基づいて判定境界を求めます。大規模な (n が大きい) データ セットについては、
ocsvmのソルバーの方がfitcsvmのソルバーよりも計算量が少なくなります。fitcsvmのソルバーでは n 行 n 列のグラム行列の計算が必要ですが、ocsvmのソルバーで必要なのは n 行 m 列の行列の形成だけです。ここで、m は拡張空間の次元数であり、ビッグ データにおいては一般に n よりもはるかに小さくなります。
参照
[1] Christianini, N., and J. C. Shawe-Taylor. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods. Cambridge, UK: Cambridge University Press, 2000.
[2] Fan, R.-E., P.-H. Chen, and C.-J. Lin. “Working set selection using second order information for training support vector machines.” Journal of Machine Learning Research, Vol. 6, 2005, pp. 1889–1918.
[3] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning, Second Edition. NY: Springer, 2008.
[4] Kecman V., T. -M. Huang, and M. Vogt. “Iterative Single Data Algorithm for Training Kernel Machines from Huge Data Sets: Theory and Performance.” Support Vector Machines: Theory and Applications. Edited by Lipo Wang, 255–274. Berlin: Springer-Verlag, 2005.
[5] Scholkopf, B., J. C. Platt, J. C. Shawe-Taylor, A. J. Smola, and R. C. Williamson. “Estimating the Support of a High-Dimensional Distribution.” Neural Comput., Vol. 13, Number 7, 2001, pp. 1443–1471.
[6] Scholkopf, B., and A. Smola. Learning with Kernels: Support Vector Machines, Regularization, Optimization and Beyond, Adaptive Computation and Machine Learning. Cambridge, MA: The MIT Press, 2002.
拡張機能
バージョン履歴
R2014a で導入参考
ClassificationSVM | CompactClassificationSVM | ClassificationPartitionedModel | predict | fitSVMPosterior | rng | quadprog (Optimization Toolbox) | fitcecoc | fitclinear | ocsvm
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)