確率分布オブジェクトのグループ化されたデータへの当てはめ
この例では、確率分布オブジェクトをグループ化された標本データに当てはめ、プロットを作成してグループごとに確率密度関数を視覚的に比較する方法を示します。
手順 1. 標本データを読み込む。
標本データを読み込みます。
load carsmall;データには、さまざまな車種およびモデルのガロンあたりの走行マイル数 (MPG) の測定値が格納され、生産国 (Origin)、モデル年 (Model_Year)、その他の車両の特性によってグループ化されています。
手順 2. categorical 配列を作成する。
Origin を categorical 配列に変換します。
Origin = categorical(cellstr(Origin));
手順 3. カーネル分布を各グループに当てはめる。
fitdist を使用し、カーネル分布を MPG データの各生産国グループに近似します。
[KerByOrig,Country] = fitdist(MPG,'Kernel','by',Origin)
KerByOrig=1×6 cell array
{1x1 prob.KernelDistribution} {1x1 prob.KernelDistribution} {1x1 prob.KernelDistribution} {1x1 prob.KernelDistribution} {1x1 prob.KernelDistribution} {1x1 prob.KernelDistribution}
Country = 6x1 cell
{'France' }
{'Germany'}
{'Italy' }
{'Japan' }
{'Sweden' }
{'USA' }
cell 配列 KerByOrig には、標本データで表されている国ごとに 1 つずつ、6 つのカーネル分布オブジェクトが含まれます。各オブジェクトは、データ、分布、およびパラメーターについての情報を保持するプロパティを含んでいます。配列 Country は、分布オブジェクトが KerByOrig に格納されるのと同じ順番で各グループの生産国をリストします。
手順 4. 各グループの pdf を計算する。
ドイツ、日本および米国の確率分布オブジェクトを抽出します。手順 3 に示されている KerByOrig の各国の位置を使用します (ドイツが 2 番目の国、日本が 4 番目の国、米国が 6 番目の国であることを示しています)。各グループの pdf を計算する。
Germany = KerByOrig{2};
Japan = KerByOrig{4};
USA = KerByOrig{6};
x = 0:1:50;
USA_pdf = pdf(USA,x);
Japan_pdf = pdf(Japan,x);
Germany_pdf = pdf(Germany,x);手順 5. 各グループの pdf をプロットする。
同じ Figure 内で各グループの確率密度関数をプロットします。
plot(x,USA_pdf,'r-') hold on plot(x,Japan_pdf,'b-.') plot(x,Germany_pdf,'k:') legend({'USA','Japan','Germany'},'Location','NW') title('MPG by Country of Origin') xlabel('MPG')
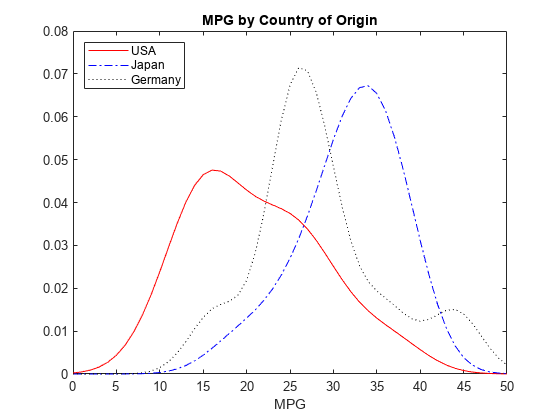
結果のプロットは、ガロンあたりの走行マイル数 (MPG) の性能が生産国 (Origin) によってどう異なるのかを示しています。このデータを使用すると、3 か国の中で米国の分布が最も広く、また分布のピークが最も低い MPG 値となります。日本は 3 か国の中で最も規則的な分布をしていて、左裾が若干大きくなっています。MPG 値のピークも日本が最も高くなっています。ドイツのピークは米国と日本の間にあり、ガロンあたり 44 マイル付近の 2 番目の山はデータ内に複数の最頻値がある可能性を示しています。
参考
関連するトピック
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)