accumarray
ベクトル要素の累積
構文
説明
B = accumarray(ind,data)ind で指定されたグループに従ってベクトル data の要素の累積を行い、データのグループを合計します。その後、各グループについて合計が計算されます。ind の値で、データが属するグループと各グループの合計が格納される出力配列 B のインデックスの両方を定義します。
グループの合計を順番に返すには、ind をベクトルとして指定します。この場合、accumarray は、インデックスが i のグループの合計を B(i) に返します。たとえば、ind = [1 1 2 2]'、data = [1 2 3 4]' の場合、B = accumarray(ind,data) は列ベクトル B = [3 7]' を返します。
グループの合計を別の形状で返すには、ind を行列として指定します。ind が m 行 n 列の行列である場合、各行はグループの割り当てと出力 B に対する n 次元のインデックスを表します。たとえば、ind に [3 4] の形式で 2 つの行が含まれている場合、data の対応する要素の合計が B の (3,4) の要素に格納されます。
インデックスが ind に現れない B の要素は、既定では 0 で埋められます。
例
入力引数
出力引数
詳細
要素の累積
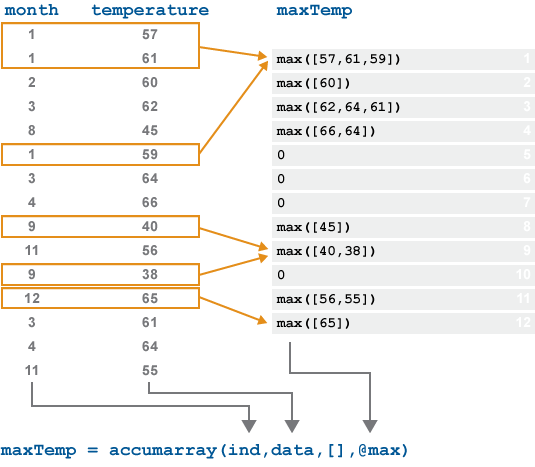
次の図は、12 か月間で測定された温度データのベクトルに対する accumarray の動作を示しています。各月の最高の測定温度値を求めるために、accumarray は、month 内に同一のインデックスをもつ temperature の値の各グループに対して関数 max を適用します。
month には、出力の 5、6、7、10 の位置を指している値はありません。既定では、それらのインデックスにおける出力 maxTemp の要素は 0 です。
ヒント
accumarrayの動作は、関数groupsummaryおよびgroupcountsに似ています。前者はグループ別に要約統計量を計算し、後者はグループの要素数をカウントします。MATLAB® のその他のグループ化機能については、データの前処理を参照してください。accumarrayの動作は、関数histcountsの動作にも似ています。histcountsはビンのエッジを使用して連続値を 1 次元の範囲にグループ化します。accumarrayは n 次元のインデックスを使用してデータをグループ化します。histcountsはビンのカウント数とビンの配置を返すことのみが可能です。accumarrayはデータに任意の関数を適用できます。
accumarrayにdata = 1を指定するとhistcountsと同じ結果が得られます。関数
sparseもaccumarrayと同様に累積を行います。sparseは 2 次元のインデックスを使用してデータをグループ化するのに対し、accumarrayは n 次元のインデックスを使用してデータをグループ化します。同一のインデックスをもつ要素が複数ある場合、
sparseは関数sum(double値の場合) または関数any(logical値の場合) を適用して出力行列にスカラーの結果を返します。accumarrayは既定では合計しますが、任意の関数をデータに適用できます。
拡張機能
バージョン履歴
R2006a より前に導入
参考
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)